











システムアーキテクチャは、ソフトウェアコンポーネントが物理的なインフラと整合するようにするため、明確な文書化に大きく依存しています。UMLデプロイメント図はこのプロセスにおける重要なアーティファクトであり、アプリケーションが存在するハードウェアおよびソフトウェア環境を可視化します。しかし、これらの図を描くことは、単にボックスと線を描くことよりもはるかに複雑です。多くのアーキテクトは、システムの真の性質を曖昧にし、デプロイメントの失敗や保守時の混乱を招く罠に陥ります。
このガイドでは、UMLデプロイメント図を構築する際に頻繁に遭遇する特定のエラーを検討します。これらの落とし穴を特定し、修正戦略を適用することで、インフラを正確に反映する図を生成でき、運用をスムーズにすることができます。
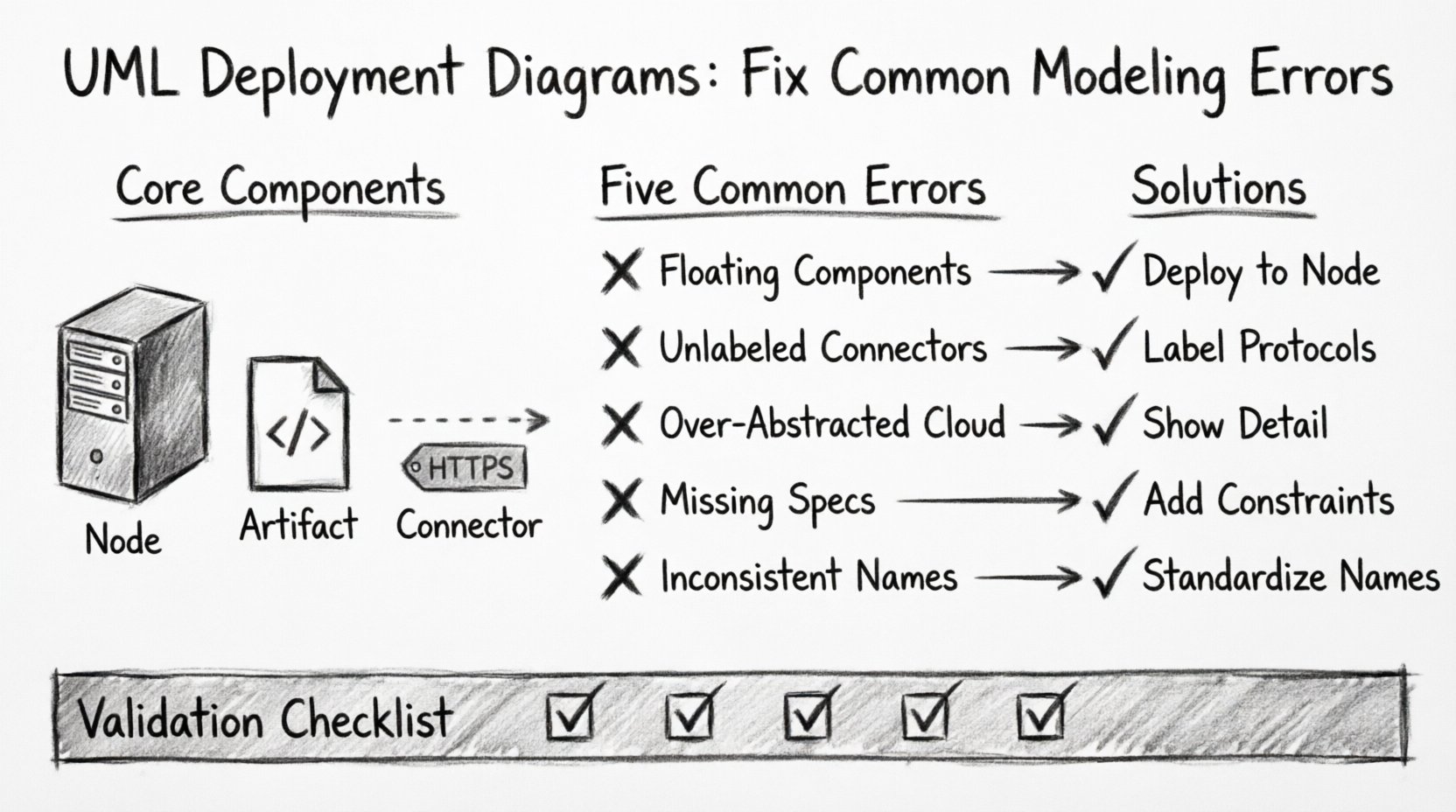
🧩 コアコンポーネントの理解
エラーの対処の前に、関係する要素について基本的な理解を確立することが不可欠です。デプロイメント図は、3つの主要な構成要素で構成されています:
- ノード: これらは物理的または仮想的なコンピューティングリソースを表します。例として、サーバー、ルーター、モバイルデバイス、クラウドインスタンスがあります。
- アーティファクト: これらはソフトウェアコンポーネントの物理的表現です。例として、実行可能ファイル、ライブラリ、データベーススキーマ、構成ファイルがあります。
- コネクタ: これらはノードとアーティファクトの間の通信経路を定義します。データ送信に使用されるプロトコルや媒体を指定します。
❌ エラー1:ノードとコンポーネントの混同
最も広範に見られる問題の一つは、ノードとコンポーネントの関係を誤認することです。多くのモデルでは、アーキテクトが特定のノードに割り当てることなく、コンポーネントをキャンバス上に直接配置します。これにより、ソフトウェアが実際にどこに存在するのかが曖昧になります。
なぜこれが起こるのか
- すべてのサーバーに対してボックスを描くよりも、コンポーネントを空間に浮かせる方が簡単だからです。
- 物理的デプロイメントと論理的デプロイメントの違いが明確でない。
- コンテナ(ノード)とコンテンツ(コンポーネント)の違いが無視されている。
影響
コンポーネントがノードに明示的にデプロイされていない場合、運用チームはハードウェア要件を特定できません。これにより、プロビジョニングの際に誤ったリソースが割り当てられる問題が発生します。また、障害の発生位置が明確でないため、トラブルシューティングが複雑になります。
修正方法
- 常にアーティファクトやコンポーネントを特定のノードインスタンスに関連付ける。
- デプロイメント関係を示すために破線を使用し、アーティファクトからノードに向かって矢印を描く。
- ソフトウェア定義(コンポーネント)と物理的インスタンス(アーティファクト)の違いを明確にする。
❌ エラー2:通信プロトコルの無視
デプロイメント図におけるコネクタは、しばしばラベルのない一般的な線として描かれます。これにより図は見やすく保たれますが、システム間の相互作用に関する重要な情報を失います。データベースノードとアプリケーションノードの間に線があることは接続性を示唆しますが、通信方法は指定されていません。
一般的な見落とし
- コネクタのラベルを空のままにする。
- ポート番号を指定しない。
- SSLやSSHなどのセキュリティプロトコルを無視する。
- 同期通信と非同期通信の違いを無視する。
プロトコルが重要な理由
ネットワークのセキュリティとパフォーマンスは、使用されるプロトコルに大きく依存します。通信がHTTP、TCP/IP、またはメッセージキューであるかどうかを明記しない図面は、セキュリティ上の脆弱性を招くことがあります。たとえば、暗号化が必要な場所で暗号化されていない通信であると仮定すると、データ漏洩につながる可能性があります。
修正方法
- すべての接続部分にプロトコル名をラベル付けする。
- 該当する場合はポート番号を含める(例:HTTPSの443)。
- 異なる種類のトラフィックには明確な線のスタイルを使用する(例:データは実線、管理用は点線)。
- 接続が暗号化されているか認証されているかを明記する。
❌ エラー3:トポロジーの抽象化しすぎ
ときには、アーキテクトが図をあまりにも単純化しようとすることがあります。たとえば、全体のデータセンターを1つのクラウドアイコンで表現するかもしれません。これは上位の経営者向けの要約には有効ですが、技術的な実装段階では失敗します。詳細なデプロイメント図は、上位の抽象化では欠けている粒度のレベルを必要とします。
抽象化が失敗するとき
- ロードバランサーの設定を定義するとき。
- 冗長性およびフェイルオーバー機構を指定するとき。
- ネットワークセグメンテーションを計画するとき。
- 特定のサービスのリソース要件を計算するとき。
修正方法
- 対象の読者を特定する。技術チームはノードレベルの詳細が必要だが、ステークホルダーは上位レベルの視点が必要な場合がある。
- ネストされた図を使用する。メイン図は上位レベルのフローを示し、複雑なノードについては詳細なサブ図を作成する。
- ファイアウォール、ゲートウェイ、ロードバランサーを明確に個別のノードとして表示する。
- 重要なサービスのインスタンス数を文書化する(例:Webサーバー3ノード)。
❌ エラー4:ハードウェアおよびソフトウェアの制約を無視する
デプロイメント図は接続性を示すだけでなく、実現可能性も示すべきです。多くのモデルでは、提案されたハードウェア上でシステムが実際に動作可能かどうかを決定する制約が省略されています。これにはCPU、メモリ、ストレージ、およびオペレーティングシステムの要件が含まれます。
欠落している制約
- オペレーティングシステムのバージョン(例:Linux Ubuntu 22.04 と Windows Server 2019)。
- 必要な実行環境(例:Java JDK 17、.NET Core)。
- リソース制限(例:8 vCPU、32GB RAM)。
- データベースのストレージ容量要件。
結果
これらの制約がなければ、デプロイメントスクリプトが失敗する可能性があります。インフラチームが必要なOSやランタイムライブラリを備えていない汎用サーバーをプロビジョニングするかもしれません。これにより、デプロイフェーズで遅延や再作業が発生します。
修正方法
- ノードにプロパティスタereotypeを追加して、OSおよびハードウェア仕様を定義する。
- アーティファクトをその特定のバージョン要件に関連付ける。
- ノードレベルで必要な環境変数または構成ファイルを文書化する。
- すべてのソフトウェアアーティファクトの依存関係バージョンについてのメモを含める。
❌ エラー5:命名規則の不整合
命名規則が不整合であると、可読性が低下する。あるノードは「Web_Server_01」と名付けられる一方で、別のノードは「Frontend_Node_A」と名付けられることがある。このような不整合は、図面を検索したり、構成管理データベースと照合したりすることを困難にする。
一般的な命名の問題
- 省略語と完全な単語を混在させる。
- 環境名を一貫性なく使用する(例:Dev、DEV、Development)。
- ノード名に不要な詳細を含める(例:「Production-Web-Server-IP-192-168-1-10」)。
- 接頭辞または接尾辞の標準がない。
修正方法
- プロジェクト用の命名規則を確立する。
- 環境に接頭辞を使用する(例:「prod-」、「dev-」)。
- 役割に接尾辞を使用する(例:「-web」、「-db」、「-cache」)。
- 静的図の名前には動的データ(IPアドレスなど)を避ける。
- すべてのチームメンバーが同じパターンを遵守することを確認する。
📊 デプロイ図の検証チェックリスト
図が正確で有用であることを確認するため、モデルを最終化する前に、以下の表を検証ガイドとして使用する。
| チェック項目 | 正しいアプローチ | 一般的なミス |
|---|---|---|
| ノードの識別 | 各ノードは物理的または論理的な処理ユニットを表す。 | ノードとコンポーネントが明確な境界なしに混在している。 |
| アーティファクトの配置 | アーティファクトは破線を使って特定のノードにデプロイされる。 | アーティファクトがデプロイ先なしに自由に浮遊している。 |
| 接続性 | 接続器にはプロトコルとポートがラベル付けされている。 | 線は一般的で、トラフィックの仕様がない。 |
| 制約 | ハードウェアおよびソフトウェア要件は、ノードに文書化されています。 | リソース要件は完全に省略されています。 |
| 一貫性 | 名前付けは、プロジェクト全体で厳格な規則に従います。 | 名前付けはランダムまたは図の全体にわたって一貫性がありません。 |
| スケーラビリティ | 負荷分散のために複数のインスタンスが表示されています。 | 単一のインスタンスは冗長性がないことを意味します。 |
🔄 反復的精練プロセス
デプロイメント図は初回の試行でほとんど完璧ではありません。アーキテクチャの変化に伴って進化します。反復的な精練プロセスは、時間の経過とともに正確性を維持するのに役立ちます。
ステップ1:論理トポロジーを下書きする
まず、データの高レベルな流れを定義します。主要なゾーン(例:DMZ、内部、外部)を特定します。主要なノードをそれぞれのゾーンに配置します。
ステップ2:物理的詳細を追加する
ノードを精査し、特定のハードウェアまたはクラウドインスタンスタイプを含めます。オペレー�ティングシステムおよび必要なランタイムを追加します。
ステップ3:相互作用を定義する
接続線を描き、プロトコルでラベル付けします。すべてのセキュリティ境界が尊重されていることを確認します(例:ゾーン間のファイアウォール)。
ステップ4:現実との照合
図を実際のインフラ構成またはデプロイメント計画と照合します。不一致があれば更新します。このステップにより、図が真実の情報源のまま保たれます。
🛡️ モデリングにおけるセキュリティ上の考慮事項
セキュリティは図作成においてしばしば後回しにされますが、設計段階に統合されるべきです。デプロイメント図は、セキュリティ監査およびペネトレーションテストのレビューにおける主要なツールです。
モデル化すべき重要なセキュリティ要素
- ファイアウォール:トラフィックがフィルタリングされる境界を明確にマークする。
- 暗号化:データが静止時および送信中に暗号化されている場所を示す。
- 認証ゾーン:ID管理システムが配置されている場所を示す。
- ネットワークセグメンテーション:重要なデータベースを公開向けのWebサーバーから分離する。
ベストプラクティス
- 公開図面に内部IPアドレスを露出しないでください。
- 機密性の高いノードには一般的な名前を使用する(例:「Kerberos_Server」ではなく「Auth_Service」など)。
- DMZ(非軍事区)を明確に強調する。
- 図面が最小権限の原則を反映していることを確認する。
📝 ダイナミックな環境の扱い方
現代のインフラは、クラウド環境における自動スケーリンググループなど、動的スケーリングに依存することが多い。静的なデプロイメント図では、この流動性を簡単に表現できない。しかし、スケーリングの能力をモデル化することは可能である。
スケーラビリティのモデル化
- ノードのインスタンス数の最小値と最大値を示す。
- 複数のノードにトラフィックを分散するロードバランサーを表示する。
- スケーリングのトリガーを文書化する(例:CPU使用率のしきい値)。
- 静的ビューでは見えない自動スケーリングのロジックを、注記を使って説明する。
🔍 メンテナンスとバージョン管理
図面が完成したら、維持管理が必要である。古くなった図面は、何も描かれていない図面よりも悪く、チームを誤解させる。図面をバージョン管理が必要な動的な文書として扱う。
メンテナンス戦略
- 図面をコードベースと併せて、中央リポジトリに保存する。
- インフラ構成の変更がデプロイされるたびに、図面を更新する。
- 図面のフッターにバージョン番号と最終更新日を含める。
- メンテナンスの責任者を特定のアーキテクトまたはチームに割り当てる。
🚀 正確性を保って前進する
一般的なモデル化の誤りを避けるには、規律と正確さへの注力が必要である。ノードとアーティファクトの関係を厳密に定義し、通信経路にラベルを付け、制約を文書化することで、成功したデプロイを支援する設計図を作成できる。これらの図面は、設計と現実の間の橋渡しの役割を果たす。この橋がしっかりしていれば、ソフトウェアの提供はより予測可能で信頼性が高くなる。
重要な点に注目する:ハードウェア、プロトコル、セキュリティ境界。適切に構築されたデプロイメント図は曖昧さを減らし、チーム全体がシステムアーキテクチャを理解できるようにする。アプローチを継続的に改善し、すべてのボックスと線がインフラ構造の広い文脈において明確な目的を持つことを確認する。
")
