











Die Sichtbarkeit der Infrastruktur ist oft der entscheidende Unterschied zwischen einem stabilen Service und einem katastrophalen Ausfall. In dieser detaillierten Darstellung untersuchen wir einen spezifischen Fall, bei dem ein Team während eines Hochverkehrsevents erhebliche Latenzprobleme und Ausfälle erlebte. Die Lösung war weder ein neuer Server noch eine Code-Optimierung, sondern eine grundlegende Veränderung der Art und Weise, wie die Architektur visualisiert und verstanden wurde. Durch die Erstellung eines präzisen Bereitstellungsdiagramms identifizierte das Ingenieurteam versteckte Engpässe und reorganisierte die Logik ihrer Infrastruktur.
Dieser Artikel dient als technische Analyse dieses Prozesses. Er beschreibt die Erstellung des Diagramms, die spezifischen architektonischen Mängel, die entdeckt wurden, sowie die anschließenden Verbesserungen. Hier gibt es keine Übertreibung, sondern lediglich die Mechanik des Systemdesigns und die praktische Anwendung visueller Dokumentation zur Lösung komplexer ingenieurwissenschaftlicher Probleme.
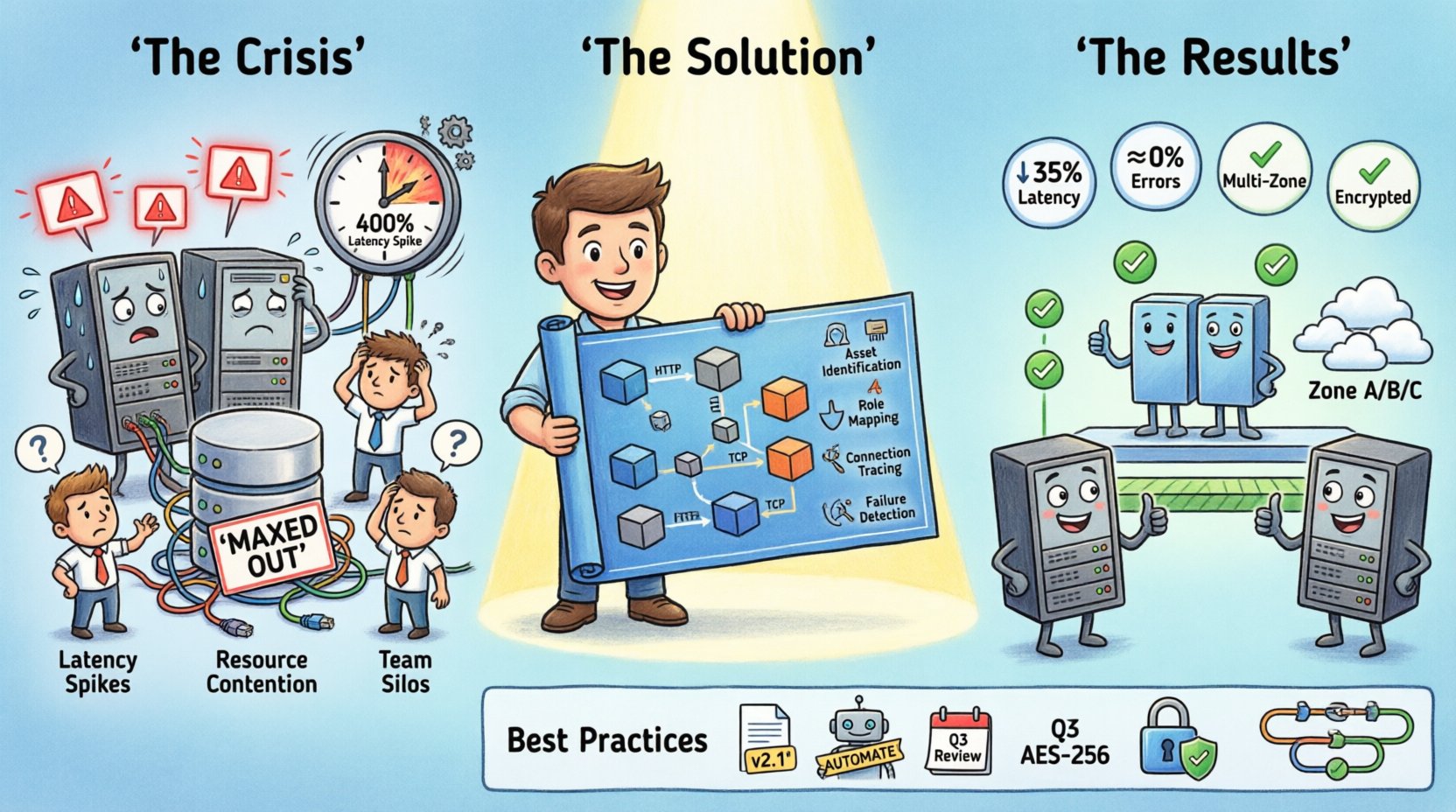
Die Situation: Ein System unter Druck 📉
Das betreffende Projekt verarbeitete erhebliche Nutzeranfragen für eine digitale Plattform. Als die Nutzerbasis wuchs, zeigte sich zunehmend Belastung in der ursprünglichen Architektur. Das Team bemerkte intermittierende Verzögerungen beim Datenabruf und gelegentliche Timeouts während der Spitzenzeiten. Standard-Monitoring-Tools zeigten hohe CPU-Auslastung an bestimmten Knoten, konnten aber nicht erklären,warumdiese Knoten stärker belastet waren als andere.
Ohne eine klare Karte der Infrastruktur wurde das Troubleshooting zu einem Ratespiel. Ingenieure starteten Dienste neu, glaubten, dass dadurch die Engpässe beseitigt würden, nur um Stunden später festzustellen, dass das Problem erneut auftrat. Das Fehlen einer einheitlichen Sicht auf die Bereitstellungs-Topologie führte dazu, dass Abhängigkeiten zwischen Diensten oft übersehen wurden. Kommunikationsprotokolle wurden angenommen, anstatt überprüft zu werden.
Wichtige Indikatoren der Krise waren:
- Latenzspitzen:Die Antwortzeiten stiegen in bestimmten Zeiträumen um 400 %.
- Ressourcenkonflikte:Datenbankverbindungen waren an bestimmten Shards ausgeschöpft.
- Bereitstellungsverwirrung:Neuer Code wurde in Umgebungen bereitgestellt, die die erforderlichen Lastverteilungssysteme nicht konfiguriert hatten.
- Team-Silos:Backend-Entwickler verstanden die Netzwerktopologie nicht, und Netzwerk-Ingenieure hatten kein Verständnis für die Anwendungslogik.
Es wurde klar, dass die physische und logische Anordnung des Systems nicht mit dem vorgesehenen Design übereinstimmte. Eine visuelle Darstellung war erforderlich, um die Kluft zwischen dem Code und der Hardware zu überbrücken.
Verständnis des Bereitstellungsdiagramms 🗺️
Ein Bereitstellungsdiagramm ist eine strukturelle Darstellung der physischen Artefakte, die in einem System bereitgestellt sind. Es zeigt die Hardware-Knoten, die darauf laufenden Softwarekomponenten und die Kommunikationspfade zwischen ihnen. Im Gegensatz zu einem Ablaufdiagramm, das sich auf Zeit und Interaktion konzentriert, fokussiert ein Bereitstellungsdiagramm auf Lage und Verbindung.
Für diese Fallstudie erfüllte das Diagramm drei entscheidende Funktionen:
- Bestandsaufnahme:Es listete jeden Server, Container und virtuellen Rechner, der derzeit eingesetzt wurde.
- Verbindungsabbildung:Es definierte, wie Daten zwischen Knoten fließen, einschließlich der Protokolltypen.
- Kapazitätsplanung:Es zeigte auf, wo Ressourcen doppelt vorhanden waren oder unzureichend waren.
Die Erstellung dieses Diagramms erforderte die Einbindung mehrerer Stakeholder. Die Betriebsteams lieferten den aktuellen Zustand der Infrastruktur. Die Entwicklerteams klärten, welche Dienste auf welchen Knoten laufen sollten. Die Sicherheitsteams überprüften die Kommunikationsgrenzen.
Die Diagrammkomponenten umfassten typischerweise:
- Knoten: Dargestellt als Quader, handelt es sich um physische Geräte wie Server, Router oder Cloud-Instanzen.
- Artefakte: Die Software- oder Hardware-Dateien, die auf den Knoten bereitgestellt werden, wie z. B. ausführbare Dateien oder Bibliotheken.
- Verbindungen: Linien, die den Kommunikationspfad zwischen Knoten oder Artefakten anzeigen.
- Schnittstellen: Die Ein- und Ausgangspunkte für die Kommunikation.
Der Abbildungsprozess: Schritt für Schritt 🔍
Das Team begann den Abbildungsprozess mit der Sammlung von Rohdaten. Sie exportierten Konfigurationsdateien aus der Orchestrierungsschicht und fragten die Überwachungsdatenbank ab. Diese Daten lieferten eine Liste aktiver Instanzen und ihrer zugewiesenen Rollen. Ziel war es, eine „einzig wahre Quelle“ zu schaffen, die der laufenden Umgebung entsprach.
Schritt 1: Identifikation von Assets
Die erste Aufgabe bestand darin, jeden aktiven Knoten zu katalogisieren. Dazu gehörten Produktions-Server, Staging-Umgebungen und Backup-Replikate. Das Team stellte fest, dass mehrere Legacy-Server weiterhin mit dem Hauptcluster verbunden waren, aber keinen Datenverkehr erhielten. Diese verbrauchten Ressourcen, ohne einen Nutzen zu bieten.
Schritt 2: Festlegung der Knotenrollen
Jeder Knoten erhielt eine spezifische Rolle. Einige fungierten als Anwendungsserver, andere als Datenbankknoten, und wieder andere dienten als Lastverteiler. Durch die klare Kennzeichnung konnten das Team erkennen, ob ein einzelner Knoten zu viele Funktionen übernahm, was eine häufige Ursache für Instabilität ist.
Schritt 3: Verfolgung der Kommunikationspfade
Dies war der kritischste Schritt. Das Team zeichnete Linien zwischen Knoten, um den Netzwerkverkehr darzustellen. Sie notierten die verwendeten Protokolle, wie z. B. HTTP, TCP oder interne Nachrichtenwarteschlangen. Dabei zeigte sich ein gravierendes Problem: Mehrere Dienste kommunizierten über unverschlüsselte Kanäle, und einige durchliefen unnötigerweise mehrere Hops.
Schritt 4: Identifikation von Einzelpunkten des Ausfalls
Sobald die Verbindungen gezeichnet waren, wurden die Risiken sichtbar. Ein bestimmter Lastverteiler war der Eingangspunkt für 80 % des Datenverkehrs. Wenn dieser Knoten ausfiel, ging das gesamte System unter. In der Darstellung war keine Redundanz konfiguriert.
Die Entdeckungsphase: Finden der Engpässe 🔧
Nach Abschluss der Darstellung analysierte das Team die visuellen Daten. Die Krise wurde nicht durch mangelnde Rechenleistung verursacht, sondern durch eine falsche Konfiguration der Anforderungsweiterleitung.
Die Darstellung zeigte, dass ein Datenbankknoten Schreibvorgänge sowohl für die Hauptanwendung als auch für einen Hintergrundberichtsdienst verarbeitete. Der Berichtsdienst erzeugte schwere Abfragen, die Tabellen sperrten und die Hauptanwendung zum Warten zwangen. Diese Abhängigkeit war in den Codekommentaren nicht dokumentiert, sondern lediglich in der visuellen Darstellung enthalten.
Zusätzlich zeigte die Darstellung, dass die Anwendungsserver in einer einzigen Verfügbarkeitszone gruppiert waren. Das bedeutete, dass ein Stromausfall in dieser Zone die gesamte Dienstleistung lahmlegen würde. Die Infrastruktur fehlte an geografischer Verteilung.
Wichtige Erkenntnisse aus der Analyse:
- Ressourcenkonflikte:Datenbank-Schreibvorgänge blockierten Lesevorgänge aufgrund gemeinsamer Nutzung des Knotens.
- Netzwerk-Latenz:Kommunikation zwischen Zonen fügte jeder Anfrage Millisekunden hinzu.
- Lücken in der Redundanz:Es waren keine Reserve-Lastverteiler vorhanden.
- Dokumentationsabweichung:Das laufende System entsprach nicht den ursprünglichen Entwurfsdokumenten.
Die Lösung visualisieren 🛠️
Sobald die Probleme identifiziert waren, aktualisierte das Team das Bereitstellungsdiagramm, um die vorgeschlagenen Änderungen widerzuspiegeln. Diese aktualisierte Version wurde zum Bauplan für die Migration. Das neue Design beinhaltete die folgenden strukturellen Änderungen:
- Diensttrennung: Der Berichtsdienst wurde auf einen dedizierten Datenbankknoten verlegt, um Sperrkonflikte zu vermeiden.
- Lastverteilung: Ein redundanter Paar von Lastverteilern wurde zum Eingangspunkt hinzugefügt.
- Geografische Verteilung: Server wurden über mehrere Verfügbarkeitszonen verteilt.
- Verbindungs-Optimierung: Direkte Verbindungen wurden für häufige Datenübertragungen hergestellt.
Das Diagramm ermöglichte es dem Team, die neue Architektur vor der Umsetzung zu simulieren. Sie konnten den Pfad einer Anfrage durch die neuen Knoten verfolgen und überprüfen, ob keine Schleifen oder Sackgassen existierten. Diese visuelle Validierung verringerte das Risiko von Bereitstellungsfehlern.
Vergleich der Infrastrukturzustände 📊
Die folgende Tabelle hebt die Unterschiede zwischen dem ursprünglichen Zustand und dem optimierten Zustand hervor, der aus der Diagrammanalyse abgeleitet wurde.
| Komponente | Ursprünglicher Zustand | Optimierter Zustand | Auswirkung |
|---|---|---|---|
| Datenbankknoten | Geteilt (App + Berichte) | Dediziert (App + Berichte) | Verringerte Konkurrenz und Latenz |
| Lastverteilung | Einzelknoten | Redundanter Paar | Verbesserte Verfügbarkeit und Fehlertoleranz |
| Bereitstellungs-Zonen | Einzelzone | Mehrzonen | Schutz vor Zonenfehlern |
| Kommunikation | Unverschlüsselt & indirekt | Verschlüsselt & direkt | Erhöhte Sicherheit und Geschwindigkeit |
| Dokumentation | Veraltet | Abgestimmt mit Diagramm | Schnelleres Troubleshooting und Onboarding |
Implementierung und Validierung ✅
Die Migration folgte dem aktualisierten Diagramm eng. Das Team stellte die Änderungen zunächst in einer Nicht-Produktionsumgebung bereit. Sie validierten, dass die neuen Verbindungen korrekt hergestellt wurden und der Datenverkehr wie erwartet weitergeleitet wurde.
Nach der Validierung wurden die Änderungen während einer Wartungsphase bereitgestellt. Die Bereitstellung erfolgte schrittweise, um Stabilität zu gewährleisten. Überwachungs-Dashboards wurden aktualisiert, um die neuen Metriken im Zusammenhang mit den Diagrammknoten zu verfolgen.
Nach der Implementierung waren die Ergebnisse sofort spürbar:
- Latenzreduzierung:Die durchschnittliche Antwortzeit sank um 35 %.
- Fehlerquote:Timeout-Fehler sanken auf nahezu null.
- Ressourceneffizienz:Die CPU-Auslastung pro Knoten normalisierte sich, was die Kosten senkte.
- Team-Effizienz:Das Onboarding neuer Ingenieure wurde schneller, da das Diagramm als Referenzleitfaden diente.
Best Practices für Bereitstellungsdiagramme 📝
Um sicherzustellen, dass Bereitstellungsdiagramme über die Zeit nutzbar bleiben, hat das Team mehrere Richtlinien übernommen. Diese Praktiken helfen, die Integrität der Dokumentation aufrechtzuerhalten, während sich das System weiterentwickelt.
1. Halten Sie Diagramme versioniert
Genau wie Code sollten Diagramme versioniert werden. Bei einer signifikanten architektonischen Änderung sollte eine neue Version des Diagramms erstellt werden. Dadurch können Teams zurückblicken und verstehen, wie sich das System entwickelt hat.
2. Automatisieren Sie, wo möglich
Manuelles Zeichnen von Diagrammen kann zu Fehlern führen. Wo Tools dies zulassen, sollte das Diagramm aus der Infrastrukturkonfiguration generiert werden. Dadurch wird sichergestellt, dass die visuelle Darstellung dem tatsächlichen Zustand entspricht.
3. Regelmäßig überprüfen
Diagramme werden schnell veraltet. Es sollte eine vierteljährliche Überprüfung geplant werden, um sicherzustellen, dass das Diagramm der aktuellen Infrastruktur entspricht. Alle Abweichungen sollten sofort aktualisiert werden.
4. Kommunikationsdetails einbeziehen
Ein Knoten reicht nicht aus. Das Diagramm muss zeigen, wie die Knoten miteinander kommunizieren. Protokoll, Portnummern und Sicherheitsanforderungen sollten auf den Verbindungen notiert werden.
5. Abhängigkeiten dokumentieren
Wenn ein Dienst von einem anderen abhängt, sollte dies im Diagramm deutlich sein. Dies hilft bei der Auswirkungsanalyse, wenn ein Dienst veraltet oder aktualisiert wird.
Technische Überlegungen zur Skalierung 📈
Skalierung geht nicht nur darum, mehr Server hinzuzufügen. Es geht darum, die Komplexität zu managen, die mit dem Wachstum einhergeht. Ein Bereitstellungsdigramm hilft, diese Komplexität zu bewältigen, indem es einen Überblick über das System bietet.
Bei der Planung der Skalierung sollten die folgenden Faktoren berücksichtigt werden:
- Horizontal gegenüber vertikal:Bestimmen Sie, ob eine Skalierung mehr Knoten oder leistungsstärkere Knoten erfordert.
- Zustandsverwaltung:Stellen Sie sicher, dass zustandsbehaftete Dienste korrekt verteilt werden.
- Netzwerkbandbreite:Überprüfen Sie, ob das Netzwerk den erhöhten Datenverkehr bewältigen kann.
- Kostenfolgen:Mehr Knoten bedeuten höhere Kosten. Das Diagramm hilft, dort Einsparungen zu realisieren.
In diesem speziellen Fall wurde die Entscheidung getroffen, horizontal zu skalieren. Das Diagramm zeigte, dass der Lastverteiler die Engstelle war. Durch Hinzufügen weiterer Anwendungs-Knoten und deren Verteilung über Zonen wurde die Last effektiv verteilt.
Gelernte Lehren aus der Krise 🎓
Die Krise brachte wertvolle Lektionen für die Ingenieurorganisation. Sie zeigte die Bedeutung visueller Dokumentation in komplexen Systemen auf.
Sichtbarkeit verhindert Blinde Flecken
Wenn Sie das System nicht sehen können, können Sie es auch nicht beheben. Das Diagramm machte die versteckten Abhängigkeiten sichtbar, sodass das Team sie beheben konnte, bevor sie zu einem schweren Ausfall führten.
Kommunikation ist entscheidend
Das Diagramm wirkte als gemeinsame Sprache zwischen Entwicklern und Betrieb. Es beseitigte Unklarheiten und stellte sicher, dass alle von derselben Vorstellung der Infrastruktur ausgingen.
Dokumentation ist Teil des Codes
Genau wie Code muss getestet werden, benötigt auch Dokumentation Wartung. Das Diagramm wurde als lebendiges Artefakt behandelt, nicht als statisches Bild.
Vorbereitung schlägt Reaktion
Hätte das Diagramm früher erstellt werden können, wäre die Krise möglicherweise vermieden worden. Proaktive Planung ist immer effektiver als reaktive Fehlerbehebung.
Abschließende Gedanken zur Architekturdarstellung 💡
Die Reise von der Krise zur Stabilität wurde durch Klarheit getrieben. Das Bereitstellungsdigramm brachte diese Klarheit. Es verwandelte eine chaotische Umgebung in ein strukturiertes System, das verwaltet und skaliert werden konnte.
Für jedes Team, das verteilte Systeme verwaltet, ist die Investition in genaue Dokumentation keine Verschwendung. Es ist eine Notwendigkeit. Die Kosten für die Erstellung eines Diagramms sind weitaus geringer als die Kosten eines Ausfallereignisses.
Je größer die Systeme werden, desto größer wird die Komplexität. Ein einfaches Diagramm kann die Details nicht mehr erfassen, bietet aber den essenziellen Rahmen, um diese Komplexität zu bewältigen. Es ermöglicht Teams, sich auf die wichtigen Verbindungen zu konzentrieren, anstatt in der Geräuschkulisse einzelner Komponenten zu versinken.
Die Fallstudie zeigt, dass das richtige Werkzeug, richtig eingesetzt, ein Projekt retten kann. Das Bereitstellungsdigramm war dieses Werkzeug. Es bot die Karte, die benötigt wurde, um sich im Infrastruktur-Labyrinth zurechtzufinden.
Für Teams, die die Stabilität ihrer Infrastruktur verbessern möchten, beginnen Sie damit, Ihren aktuellen Zustand abzubilden. Identifizieren Sie die Knoten, die Verbindungen und die Abhängigkeiten. Sobald Sie die Karte haben, wird der Weg zur Optimierung klar.

