











A visibilidade da infraestrutura muitas vezes é a diferença entre um serviço estável e uma falha catastrófica. Neste relato detalhado, exploramos um cenário específico em que uma equipe enfrentou problemas graves de latência e tempo de inatividade durante um evento de grande tráfego. A solução não foi um novo servidor nem uma otimização de código, mas uma mudança fundamental na forma como a arquitetura era visualizada e compreendida. Ao construir um diagrama de implantação preciso, a equipe de engenharia identificou gargalos ocultos e reestruturou a lógica da sua infraestrutura.
Este artigo serve como uma análise técnica desse processo. Detalha a criação do diagrama, os defeitos arquitetônicos específicos descobertos e as melhorias subsequentes. Não há exagero aqui, apenas os mecanismos do design de sistemas e a aplicação prática da documentação visual para resolver problemas de engenharia complexos.
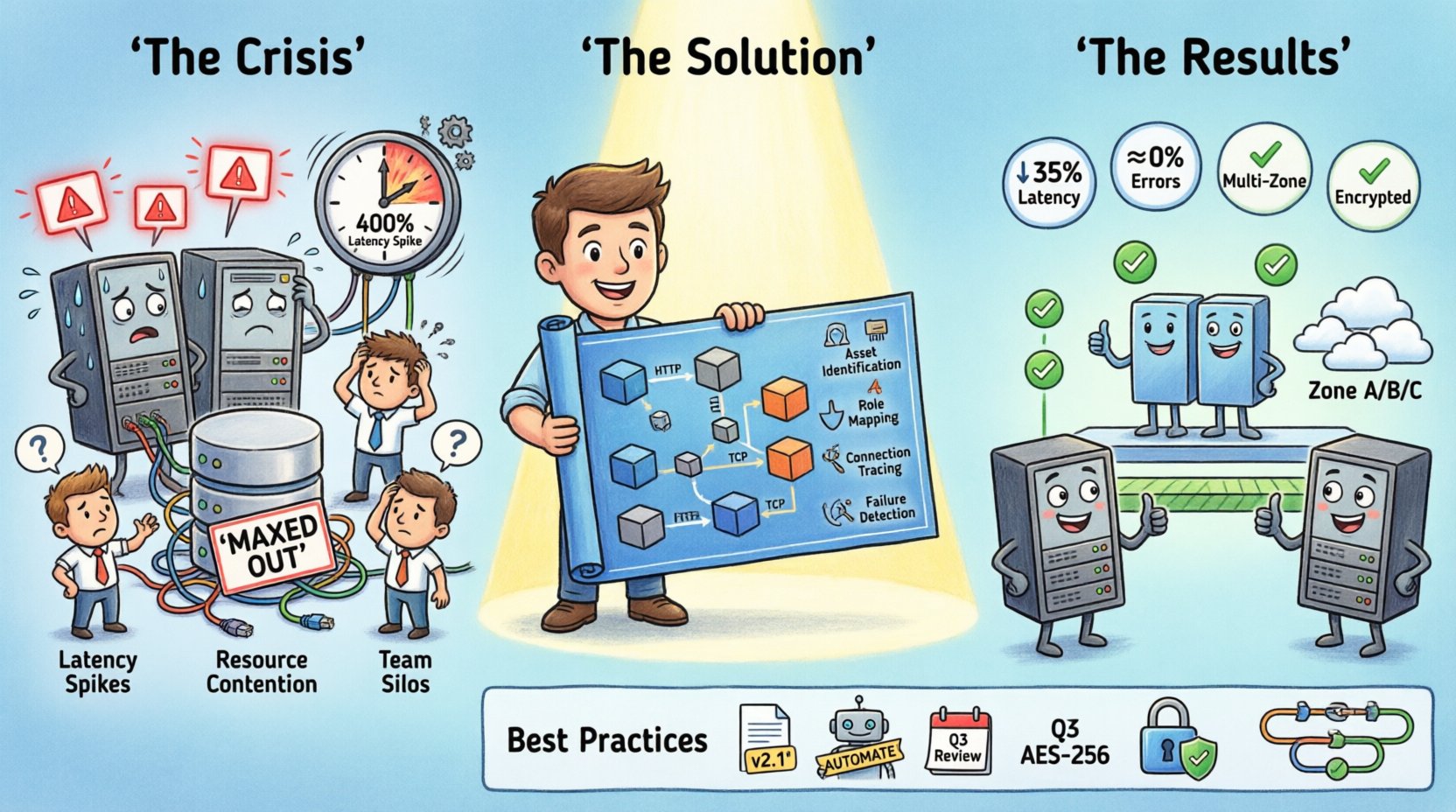
A Situação: Um Sistema Sob Pressão 📉
O projeto em questão lidava com um tráfego significativo de usuários para uma plataforma digital. À medida que a base de usuários crescia, a arquitetura inicial começou a apresentar sinais de tensão. A equipe notou atrasos intermitentes na recuperação de dados e tempos limite ocasionais durante os horários de pico. Ferramentas padrão de monitoramento indicavam uso elevado da CPU em nós específicos, mas não explicavampor queessas máquinas estavam sob estresse em comparação com as outras.
Sem um mapa claro da infraestrutura, o diagnóstico tornou-se um jogo de adivinhação. Engenheiros reiniciavam serviços, acreditando que isso aliviaria a congestão, só para o problema reaparecer algumas horas depois. A ausência de uma visão unificada da topologia de implantação significava que dependências entre serviços eram frequentemente ignoradas. Protocolos de comunicação eram assumidos em vez de verificados.
Indicadores-chave da crise incluíam:
- Picos de Latência:Os tempos de resposta aumentaram em 400% durante janelas específicas.
- Concorrência de Recursos:As conexões com o banco de dados estavam no máximo em shards específicos.
- Confusão na Implantação:Novo código estava sendo implantado em ambientes que não tinham os balanceadores de carga necessários configurados.
- Ilhas de Equipe:Desenvolvedores de back-end não compreendiam a topologia de rede, e engenheiros de rede não tinham visão sobre a lógica da aplicação.
Ficou claro que o layout físico e lógico do sistema não estava alinhado com o projeto pretendido. Uma representação visual era necessária para preencher a lacuna entre o código e o hardware.
Compreendendo o Diagrama de Implantação 🗺️
Um diagrama de implantação é uma representação estrutural dos artefatos físicos implantados em um sistema. Mostra os nós de hardware, os componentes de software em execução neles e os caminhos de comunicação entre eles. Diferentemente de um diagrama de sequência, que foca no tempo e na interação, um diagrama de implantação foca na localização e na conectividade.
Para este estudo de caso, o diagrama cumpriu três propósitos críticos:
- Inventário:Listou todos os servidores, contêineres e máquinas virtuais atualmente em uso.
- Mapeamento de Conexão:Definiu como os dados fluíam entre os nós, incluindo os tipos de protocolo.
- Planejamento de Capacidade:Destacou onde os recursos estavam duplicados ou insuficientes.
Criar este diagrama exigiu a contribuição de múltos interessados. As equipes de operações forneceram o estado atual da infraestrutura. As equipes de desenvolvimento esclareceram quais serviços pertenciam a quais nós. As equipes de segurança verificaram os limites de comunicação.
Os componentes do diagrama incluíam tipicamente:
- Nós: Representados como cuboides, esses são dispositivos físicos como servidores, roteadores ou instâncias em nuvem.
- Artifacts: Os arquivos de software ou hardware implantados nos nós, como arquivos executáveis ou bibliotecas.
- Conectores: Linhas que mostram o caminho de comunicação entre nós ou artefatos.
- Interfaces: Os pontos de entrada e saída para comunicação.
O Processo de Mapeamento: Passo a Passo 🔍
A equipe começou o processo de mapeamento coletando dados brutos. Eles exportaram arquivos de configuração da camada de orquestração e consultaram o banco de dados de monitoramento. Esses dados forneceram uma lista de instâncias ativas e seus papéis atribuídos. O objetivo era criar uma “única fonte de verdade” que correspondesse ao ambiente em execução.
Passo 1: Identificação de Ativos
A primeira tarefa foi catalogar cada nó ativo. Isso incluía servidores de produção, ambientes de homologação e réplicas de backup. A equipe descobriu que vários servidores legados ainda estavam conectados ao cluster principal, mas não estavam recebendo tráfego. Eles estavam consumindo recursos sem fornecer valor.
Passo 2: Definição dos Papéis dos Nós
Cada nó foi atribuído a um papel específico. Alguns atuavam como servidores de aplicação, outros como nós de banco de dados e alguns serviam como balanceadores de carga. Ao rotular esses papéis claramente, a equipe pôde verificar se um único nó estava realizando muitas funções, uma causa comum de instabilidade.
Passo 3: Rastreamento dos Caminhos de Comunicação
Este foi o passo mais crítico. A equipe desenhou linhas entre os nós para representar o tráfego de rede. Eles anotaram os protocolos utilizados, como HTTP, TCP ou filas de mensagens internas. Isso revelou um problema grave: vários serviços estavam se comunicando por canais não criptografados, e alguns estavam percorrendo múltiplos saltos desnecessariamente.
Passo 4: Identificação de Pontos Únicos de Falha
Assim que as conexões foram desenhadas, o diagrama tornou os riscos visíveis. Um balanceador de carga específico era a porta de entrada para 80% do tráfego. Se esse nó falhasse, todo o sistema entraria em colapso. Não havia redundância configurada no diagrama.
A Fase de Descoberta: Encontrando o Engasgo 🔧
Com o diagrama completo, a equipe analisou os dados visuais. A crise não foi causada pela falta de poder de processamento, mas por uma má configuração na forma como as requisições eram roteadas.
O diagrama revelou que um nó de banco de dados estava tratando operações de gravação para a aplicação principal e um serviço de relatórios em segundo plano. O serviço de relatórios gerava consultas pesadas que bloqueavam tabelas, fazendo com que a aplicação principal aguardasse. Essa dependência não estava documentada nos comentários do código, apenas no layout visual.
Além disso, o diagrama mostrou que os servidores de aplicação estavam agrupados em uma única zona de disponibilidade. Isso significava que uma falha de energia nessa zona específica derrubaria todo o serviço. A infraestrutura carecia de distribuição geográfica.
Principais Descobertas da Análise:
- Concorrência de Recursos:Escritas no banco de dados estavam bloqueando leituras devido ao uso compartilhado do nó.
- Latência de Rede:A comunicação entre zonas adicionou milissegundos a cada requisição.
- Falhas de Redundância:Não havia balanceadores de carga em espera.
- Desalinhamento da Documentação:O sistema em execução não correspondia aos documentos de design originais.
Visualizando a Solução 🛠️
Uma vez que os problemas foram identificados, a equipe atualizou o diagrama de implantação para refletir as mudanças propostas. Essa versão atualizada tornou-se o plano mestre para a migração. O novo design incluiu as seguintes alterações estruturais:
- Separação de Serviços: O serviço de relatórios foi movido para um nó de banco de dados dedicado para evitar conflitos de bloqueio.
- Balanceamento de Carga: Um par redundante de balanceadores de carga foi adicionado ao ponto de entrada.
- Distribuição Geográfica: Os servidores foram distribuídos por múltiplas zonas de disponibilidade.
- Otimização de Conexão: Conexões diretas foram estabelecidas para trocas de dados de alta frequência.
O diagrama permitiu à equipe simular a nova arquitetura antes de implementá-la. Eles podiam rastrear o caminho de uma solicitação pelos novos nós e verificar que não existiam loops ou becos sem saída. Essa validação visual reduziu o risco de erros na implantação.
Comparação dos Estados da Infraestrutura 📊
A tabela a seguir destaca as diferenças entre o estado inicial e o estado otimizado derivado da análise do diagrama.
| Componente | Estado Inicial | Estado Otimizado | Impacto |
|---|---|---|---|
| Nós de Banco de Dados | Compartilhado (Aplicativo + Relatórios) | Dedicado (Aplicativo + Relatórios) | Redução de contenção e latência |
| Balanceadores de Carga | Nó Único | Par Redundante | Melhor disponibilidade e tolerância a falhas |
| Zonas de Implantação | Zona Única | Multi-Zona | Proteção contra falhas de zona |
| Comunicação | Não criptografado e indireto | Criptografado e direto | Segurança e velocidade aprimoradas |
| Documentação | Desatualizado | Sincronizado com o Diagrama | Diagnóstico e onboarding mais rápidos |
Implementação e Validação ✅
A migração seguiu de perto o diagrama atualizado. A equipe preparou as alterações em um ambiente não produtivo primeiro. Validaram que as novas conexões foram estabelecidas corretamente e que o tráfego estava sendo roteado conforme esperado.
Uma vez validadas, as alterações foram implantadas durante uma janela de manutenção. A implantação foi executada em fases para garantir a estabilidade. Os painéis de monitoramento foram atualizados para rastrear as novas métricas associadas aos nós do diagrama.
Após a implementação, os resultados foram imediatos:
- Redução de Latência:O tempo médio de resposta caiu em 35%.
- Taxa de Erros:Erros de tempo limite diminuíram quase para zero.
- Eficiência de Recursos:O uso de CPU por nó foi normalizado, reduzindo os custos.
- Eficiência da Equipe:O onboarding de novos engenheiros tornou-se mais rápido, pois o diagrama serviu como guia de referência.
Melhores Práticas para Diagramas de Implantação 📝
Para garantir que os diagramas de implantação permaneçam úteis ao longo do tempo, a equipe adotou várias diretrizes. Essas práticas ajudam a manter a integridade da documentação à medida que o sistema evolui.
1. Mantenha os Diagramas Versionados
Assim como o código, os diagramas devem ser versionados. Quando ocorre uma mudança arquitetônica significativa, deve ser criada uma nova versão do diagrama. Isso permite que as equipes voltem atrás e compreendam como o sistema evoluiu.
2. Automatize Quando Possível
O diagrama manual pode levar a erros. Onde as ferramentas permitirem, o diagrama deve ser gerado a partir da configuração da infraestrutura. Isso garante que a representação visual corresponda ao estado real.
3. Revise Regularmente
Diagramas ficam desatualizados rapidamente. Deve ser agendada uma revisão trimestral para garantir que o diagrama corresponda à infraestrutura atual. Quaisquer discrepâncias devem ser atualizadas imediatamente.
4. Inclua Detalhes de Comunicação
Um nó não é suficiente. O diagrama deve mostrar como os nós se comunicam entre si. O protocolo, números de porta e requisitos de segurança devem ser indicados nos conectores.
5. Documente Dependências
Se um serviço depende de outro, isso deve ser claro no diagrama. Isso ajuda na análise de impacto quando um serviço é descontinuado ou atualizado.
Considerações Técnicas para Escalabilidade 📈
Escalabilidade não é apenas sobre adicionar mais servidores. É sobre gerenciar a complexidade que vem com o crescimento. Um diagrama de implantação ajuda a gerenciar essa complexidade fornecendo uma visão de alto nível do sistema.
Ao planejar a escalabilidade, considere os seguintes fatores:
- Horizontal vs. Vertical: Determine se a escalabilidade exige mais nós ou nós mais potentes.
- Gerenciamento de Estado: Certifique-se de que os serviços com estado estejam distribuídos corretamente.
- Largura de Banda de Rede: Verifique se a rede pode lidar com o aumento no volume de tráfego.
- Implicações de Custos: Mais nós significam custos mais altos. O diagrama ajuda a visualizar onde podem ser feitas economias.
Neste caso específico, a decisão foi escalar horizontalmente. O diagrama mostrou que o balanceador de carga era o gargalo. Ao adicionar mais nós de aplicação e distribuí-los por zonas, a carga foi compartilhada de forma eficaz.
Lições Aprendidas com a Crise 🎓
A crise proporcionou lições valiosas para a organização de engenharia. Destacou a importância da documentação visual em sistemas complexos.
Visibilidade Evita Pontos Cegos
Quando você não consegue ver o sistema, não consegue consertá-lo. O diagrama tornou as dependências ocultas visíveis, permitindo que a equipe as abordasse antes que causassem uma falha grave.
Comunicação é a Chave
O diagrama atuou como uma linguagem comum entre desenvolvedores e operações. Eliminou ambiguidades e garantiu que todos estivessem trabalhando com a mesma compreensão da infraestrutura.
Documentação é Parte do Código
Assim como o código precisa de testes, a documentação precisa de manutenção. O diagrama foi tratado como um artefato vivo, e não como uma imagem estática.
Preparação Vence a Reação
Se o diagrama tivesse sido criado antes, a crise poderia ter sido evitada. Planejamento proativo é sempre mais eficaz do que solução reativa de problemas.
Pensamentos Finais sobre a Visualização de Arquitetura 💡
A jornada da crise à estabilidade foi impulsionada pela clareza. O diagrama de implantação forneceu essa clareza. Transformou um ambiente caótico em um sistema estruturado que poderia ser gerenciado e escalado.
Para qualquer equipe que gerencia sistemas distribuídos, investir tempo em documentação precisa não é um desperdício. É uma necessidade. O custo de criar um diagrama é muito menor do que o custo de um evento de indisponibilidade.
À medida que os sistemas crescem, a complexidade aumenta. Um diagrama simples já não consegue capturar todos os detalhes, mas fornece a estrutura essencial necessária para navegar essa complexidade. Permite que as equipes se concentrem nas conexões importantes, em vez de se perderem no ruído dos componentes individuais.
O estudo de caso demonstra que a ferramenta certa, usada corretamente, pode salvar um projeto. O diagrama de implantação foi essa ferramenta. Forneceu o mapa necessário para navegar pelo labirinto da infraestrutura.
Para equipes que buscam melhorar a estabilidade de sua infraestrutura, comece mapeando seu estado atual. Identifique os nós, as conexões e as dependências. Assim que tiver o mapa, o caminho para a otimização torna-se claro.

