











インフラ構成の可視化は、安定したサービスと深刻な障害の間を分けることが多い。この詳細な事例では、高トラフィックイベント中に深刻な遅延問題とダウンタイムに直面したチームの状況を検証する。解決策は新しいサーバーでも、コードの最適化でもなく、アーキテクチャを可視化・理解する方法の根本的な変化だった。正確なデプロイメント図を構築することで、エンジニアリングチームは隠れたボトルネックを特定し、インフラ構造の論理を再構築した。
この記事はそのプロセスの技術的分析である。図の作成過程、発見された具体的なアーキテクチャ上の欠陥、そしてその後の改善点を詳述する。ここには誇張はなく、システム設計のメカニズムと、複雑なエンジニアリング問題を解決するために視覚的ドキュメントを実践的に活用する姿勢のみが存在する。
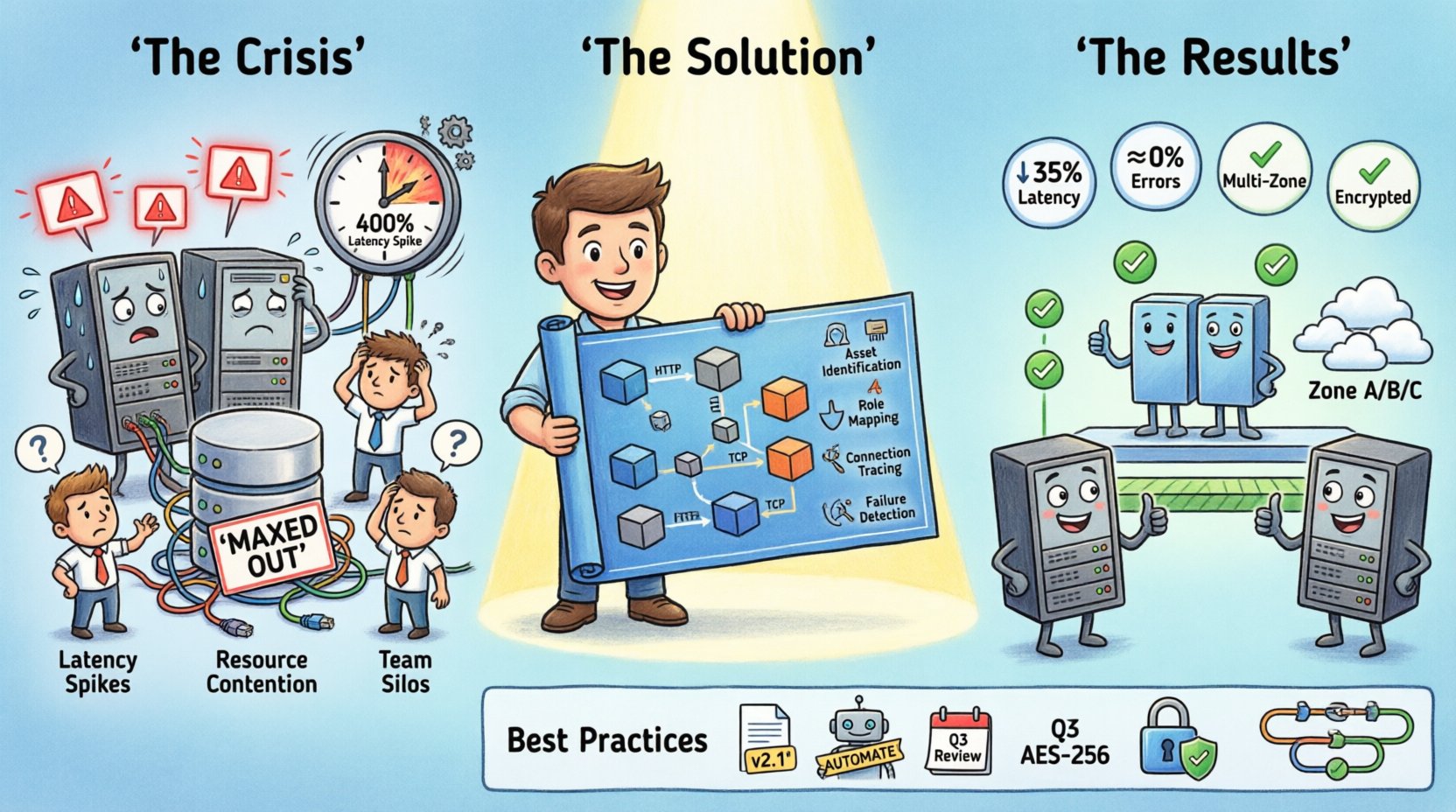
状況:圧力にさらされたシステム 📉
対象のプロジェクトはデジタルプラットフォームの大きなユーザー流量を処理していた。ユーザー数が増加するにつれ、初期のアーキテクチャに負荷がかかるようになり始めた。チームはデータ取得の間欠的な遅延や、ピーク時間帯の時折発生するタイムアウトに気づいた。標準的なモニタリングツールは特定のノードでCPU使用率が高いことを示していたが、なぜそのノードだけが他のノードと比べてストレスを受けていたのかは説明できなかった。なぜそのノードが他のノードと比べてストレスを受けていたのか。
インフラ構成の明確なマップがなければ、トラブルシューティングは当てずっぽうのゲームになる。エンジニアたちはサービスを再起動し、混雑が解消すると信じていたが、数時間後に問題が再発した。デプロイメントトポロジーの統一された視点が欠如していたため、サービス間の依存関係がしばしば見過ごされた。通信プロトコルは検証されず、単に仮定されたままであった。
危機の主な兆候には以下が含まれた:
- 遅延の急上昇:特定の時間帯に応答時間が400%増加した。
- リソース競合:特定のシャードでデータベース接続が上限に達していた。
- デプロイメントの混乱:新しいコードが、必要なロードバランサーが設定されていない環境にデプロイされていた。
- チームの孤立:バックエンド開発者はネットワークトポロジーを理解しておらず、ネットワークエンジニアはアプリケーションロジックの洞察を持てていなかった。
システムの物理的・論理的なレイアウトが意図された設計と一致していないことが明らかになった。コードとハードウェアの間のギャップを埋めるために、視覚的な表現が必要だった。
デプロイメント図の理解 🗺️
デプロイメント図は、システムにデプロイされた物理的アーティファクトの構造的表現である。ハードウェアノード、それら上で実行されているソフトウェアコンポーネント、およびそれらの間の通信経路を示す。シーケンス図が時間と相互作用に注目するのに対し、デプロイメント図は位置と接続性に注目する。
この事例研究において、図は3つの重要な目的を果たした:
- 資産管理:現在使用中のすべてのサーバー、コンテナ、仮想マシンをリストアップした。
- 接続マッピング:ノード間のデータの流れ、プロトコルの種類を含めて定義した。
- 容量計画:リソースが重複しているか、不足している場所を強調した。
この図を作成するには、複数のステークホルダーからの入力が必要だった。運用チームがインフラ構成の現在の状態を提供した。開発チームがどのサービスがどのノードに配置されるべきかを明確にした。セキュリティチームが通信境界を検証した。
図の構成要素には通常以下が含まれた:
- ノード: 立方体として表現されるこれらは、サーバー、ルーター、またはクラウドインスタンスなどの物理デバイスである。
- アーティファクト: ノードにデプロイされたソフトウェアまたはハードウェアファイルで、実行可能ファイルやライブラリなどが含まれる。
- コネクタ: ノードまたはアーティファクト間の通信経路を示す線。
- インターフェース: 通信の入口と出口。
マッピングプロセス:ステップバイステップ 🔍
チームは、マッピングプロセスを開始するために原始データを収集した。オーケストレーション層から構成ファイルをエクスポートし、モニタリングデータベースを照会した。このデータにより、アクティブなインスタンスとその割り当てられた役割の一覧が得られた。目的は、実行中の環境と一致する「唯一の真実のソース」を作成することだった。
ステップ1:資産の識別
最初の作業は、すべてのアクティブなノードを一覧化することだった。これには本番サーバー、ステージング環境、バックアップレプリカが含まれた。チームは、いくつかのレガシーサーバーがまだメインクラスターに接続されているが、トラフィックを受信していないことを発見した。これらは価値を提供せずにリソースを消費していた。
ステップ2:ノードの役割の定義
各ノードには特定の役割が割り当てられた。一部はアプリケーションサーバーとして、一部はデータベースノードとして、一部はロードバランサーとして機能した。これらの役割を明確にラベル付けすることで、単一のノードが多すぎる機能を担っているかどうかを把握でき、これは不安定さの一般的な原因だった。
ステップ3:通信経路の追跡
これは最も重要なステップだった。チームはノード間の線を引いてネットワークトラフィックを表した。使用されたプロトコル(HTTP、TCP、または内部メッセージキューなど)を記録した。これにより重大な問題が明らかになった:いくつかのサービスが暗号化されていないチャネルで通信しており、一部は不要に複数のホップを経由していた。
ステップ4:単一障害点の特定
接続が描かれた後、図はリスクを可視化した。特定のロードバランサーがトラフィックの80%を経由していた。このノードが故障すれば、システム全体がダウンする。図には冗長性が設定されていなかった。
発見フェーズ:ボトルネックの特定 🔧
図が完成した後、チームは視覚データを分析した。危機の原因は処理能力の不足ではなく、リクエストのルーティング方法の誤設定だった。
図から、データベースノードがメインアプリケーションとバックグラウンドレポートサービスの両方の書き込み操作を処理していることが明らかになった。レポートサービスが重いクエリを生成し、テーブルをロックすることで、メインアプリケーションが待機する状態になっていた。この依存関係はコードコメントには記載されておらず、視覚的なレイアウトにのみ記載されていた。
さらに、図からアプリケーションサーバーが単一の可用性ゾーンに集中していることがわかった。これは、その特定のゾーンで電力障害が発生すれば、サービス全体がダウンすることを意味した。インフラは地理的な分散が欠けていた。
分析からの主な発見:
- リソース競合: データベースの書き込みが、共有ノードの使用により読み込みをブロッキングしていた。
- ネットワーク遅延: ゾーン間通信により、すべてのリクエストにミリ秒が追加されていた。
- 冗長性の欠如: スタンバイ用のロードバランサーが存在しなかった。
- ドキュメントのずれ: 実行中のシステムは、元の設計書と一致していなかった。
ソリューションの可視化 🛠️
問題が特定された後、チームは提案された変更を反映するためにデプロイメント図を更新した。この更新されたバージョンが移行のための設計図となった。新しい設計には以下の構造的変更が含まれていた:
- サービスの分離: レポートサービスは、ロック競合を防ぐために専用のデータベースノードに移動された。
- 負荷分散: エントリーポイントに冗長な負荷分散装置のペアが追加された。
- 地理的分散: サーバーは複数の可用性ゾーンに分散された。
- 接続最適化: 高頻度のデータ交換には直接接続が確立された。
この図は、チームが新しいアーキテクチャを実装する前にシミュレーションできるようにした。新しいノードを経由するリクエストの経路を追跡でき、ループや行き止まりが存在しないことを確認できた。この視覚的検証により、デプロイエラーのリスクが低減された。
インフラ構成状態の比較 📊
以下の表は、図の分析から導き出された初期状態と最適化状態の違いを強調している。
| コンポーネント | 初期状態 | 最適化状態 | 影響 |
|---|---|---|---|
| データベースノード | 共有(アプリ + レポート) | 専用(アプリ + レポート) | 競合と遅延の低減 |
| 負荷分散装置 | 単一ノード | 冗長ペア | 可用性と障害耐性の向上 |
| デプロイメントゾーン | 単一ゾーン | マルチゾーン | ゾーンレベルの障害に対する保護 |
| 通信 | 暗号化されておらず、間接的 | 暗号化されており、直接的 | 強化されたセキュリティと高速性 |
| ドキュメント | 古くなっている | 図と同期済み | 迅速なトラブルシューティングとオンボーディング |
実装と検証 ✅
移行は更新された図に closely した。チームはまず非本番環境で変更をステージングした。新しい接続が正しく確立されていること、およびトラフィックが想定通りにルーティングされていることを検証した。
検証が完了した後、変更はメンテナンスウィンドウ中に展開された。展開は段階的に行われ、安定性を確保した。図のノードに関連する新しいメトリクスを追跡するために、モニタリングダッシュボードが更新された。
実装後、結果は直ちに現れた:
- 遅延の低減: 平均応答時間が35%低下した。
- エラー率: タイムアウトエラーはほぼゼロに減少した。
- リソース効率: ノードごとのCPU使用率が正常化され、コストが削減された。
- チームの効率: 図が参考ガイドとして機能したため、新規エンジニアのオンボーディングが迅速になった。
デプロイメント図のベストプラクティス 📝
デプロイメント図が長期間にわたり有用であることを保証するため、チームはいくつかのガイドラインを採用した。これらの実践は、システムの進化に伴いドキュメントの整合性を維持するのに役立つ。
1. 図をバージョン管理する
コードと同様に、図もバージョン管理するべきである。重要なアーキテクチャの変更が発生した際には、図の新しいバージョンを作成すべきである。これにより、チームはシステムの進化の過程を振り返り、理解できるようになる。
2. 可能な限り自動化する
手動での図作成はエラーを招く可能性がある。ツールが許す限り、図はインフラ構成から生成すべきである。これにより、視覚的な表現が実際の状態と一致することが保証される。
3. 定期的に見直す
図はすぐに古くなる。図が現在のインフラ構成と一致していることを確認するために、四半期ごとのレビューをスケジュールすべきである。不一致が見つかった場合は、直ちに更新すべきである。
4. 通信の詳細を含める
ノードだけでは不十分である。図はノード間の通信方法を示すべきである。プロトコル、ポート番号、セキュリティ要件は接続部分に明記すべきである。
5. 依存関係を文書化する
サービスが他のサービスに依存している場合、その点は図中に明確に示されるべきです。これにより、サービスが非推奨または更新された際の影響分析が容易になります。
スケーリングにおける技術的考慮事項 📈
スケーリングとは単にサーバーを追加することだけではありません。成長に伴う複雑さを管理することです。デプロイメント図はシステムの高レベルな視点を提供することで、この複雑さを管理するのに役立ちます。
スケーリングを計画する際には、以下の要素を検討してください:
- 水平スケーリング vs. 垂直スケーリング:スケーリングに必要なのは、より多くのノードか、より強力なノードかを判断してください。
- 状態管理:ステートフルなサービスが正しく分散されていることを確認してください。
- ネットワーク帯域幅:ネットワークが増加するトラフィック量を処理できるか確認してください。
- コストへの影響:より多くのノードは、より高いコストを意味します。図は、節約できるポイントを可視化するのに役立ちます。
この特定のケースでは、水平スケーリングを採用することになりました。図からロードバランサーがボトルネックであることが明らかになりました。アプリケーションノードを追加し、ゾーンにまたがって分散することで、負荷が効果的に共有されました。
危機から学んだ教訓 🎓
この危機は、エンジニアリング組織にとって貴重な教訓を提供しました。複雑なシステムにおける視覚的ドキュメントの重要性が浮き彫りになりました。
可視化が盲点を防ぐ
システムが見えなければ、それを修正することはできません。図により、隠れた依存関係が可視化され、チームは重大な障害が発生する前にそれらに対処できるようになりました。
コミュニケーションが鍵である
図は開発者と運用チームの間の共通言語として機能しました。曖昧さが排除され、全員がインフラ構造について同じ理解に基づいて作業できるようになりました。
ドキュメントはコードの一部である
コードがテストを必要とするのと同じように、ドキュメントも保守が必要です。図は静的な画像ではなく、動的な資産として扱われました。
準備が反応より優れる
図が earlier に作成されていたら、危機は回避できたかもしれません。予防的な計画は、反応型のトラブルシューティングよりも常に効果的です。
アーキテクチャ可視化についての最終的な考察 💡
危機から安定への道のりは、明確さによって駆動されました。デプロイメント図がその明確さを提供しました。混沌とした環境を、管理・スケーリングが可能な構造化されたシステムに変革しました。
分散システムを管理するすべてのチームにとって、正確なドキュメント作成に時間を投資することは無駄ではありません。それは必須です。図を作成するコストは、ダウンタイムイベントのコストよりもはるかに低いです。
システムが成長するにつれて、複雑性が増します。単純な図ではもはやすべての詳細を捉えられませんが、その複雑さを乗り越えるために必要な基本的な枠組みを提供します。チームは個々のコンポーネントのノイズに迷わずに、重要な接続に注目できるようになります。
この事例研究は、適切なツールを正しく使用すればプロジェクトを救えることを示しています。デプロイメント図がそのツールでした。インフラ構造の迷宮を進むために必要な地図を提供しました。
インフラ構造の安定性を向上させたいチームは、まず現在の状態をマッピングすることから始めましょう。ノード、接続、依存関係を特定してください。マップができれば、最適化への道筋が明確になります。

