











Widoczność infrastruktury często decyduje o różnicy między stabilną usługą a katastrofalnym awarią. W tym szczegółowym opisie analizujemy konkretny przypadek, w którym zespół napotkał poważne problemy z opóźnieniami i przestojami podczas wydarzenia o dużym natężeniu ruchu. Rozwiązaniem nie była nowa maszyna, ani optymalizacja kodu, ale fundamentalna zmiana sposobu wizualizacji i zrozumienia architektury. Budując dokładny schemat wdrożenia, zespół inżynieryjny wykrył ukryte węzły zatłoczenia i przebudował logikę swojej infrastruktury.
Ten artykuł stanowi techniczną analizę tego procesu. Opisuje tworzenie schematu, konkretne wykryte wady architektoniczne oraz kolejne poprawki. Tu nie ma żadnego szumu – tylko mechanizmy projektowania systemu i praktyczne zastosowanie dokumentacji wizualnej do rozwiązywania skomplikowanych problemów inżynieryjnych.
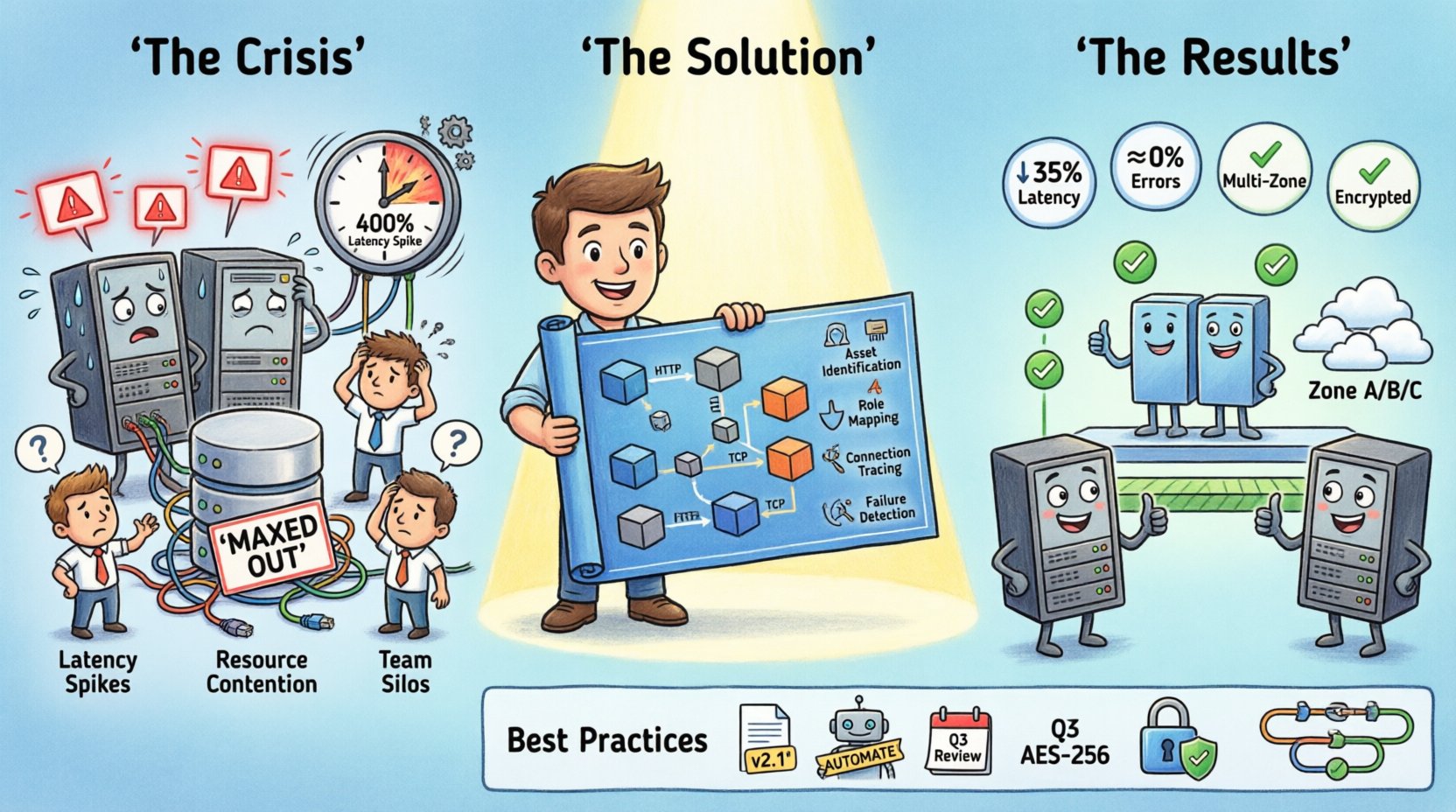
Sytuacja: System pod presją 📉
Projekt w kwestii obsługuje znaczne obciążenie ruchu użytkowników dla platformy cyfrowej. Wraz ze wzrostem liczby użytkowników, początkowa architektura zaczęła wykazywać objawy nadmiernego obciążenia. Zespół zauważył przerywane opóźnienia w pobieraniu danych oraz okazjonalne przekroczenia czasu oczekiwania w godzinach szczytu. Standardowe narzędzia monitoringu wskazywały wysokie zużycie CPU na określonych węzłach, ale nie wyjaśniały, dlaczego te węzły były obciążone w porównaniu do innych.dlaczegote węzły były obciążone w porównaniu do innych.
Bez jasnego mapowania infrastruktury, diagnozowanie problemów przeszło w grę zgadywania. Inżynierowie restartowali usługi, wierząc, że to rozwiąże zator, by po kilku godzinach zauważyć, że problem się powtarza. Brak jednolitego obrazu topologii wdrożenia oznaczał, że zależności między usługami często były pomijane. Protokoły komunikacji były domniemane, a nie potwierdzone.
Kluczowe objawy kryzysu obejmowały:
- Szybkie wzrosty opóźnień:Czas odpowiedzi wzrósł o 400% w określonych okresach.
- Konflikty zasobów:Połączenia z bazą danych były maksymalnie obciążone na określonych shardach.
- Zmieszanie w wdrożeniu:Nowy kod był wdrażany w środowiskach, które nie miały skonfigurowanych niezbędnych balansujących obciążenia.
- Szybki zespół:Programiści backendu nie rozumieli topologii sieci, a inżynierowie sieci nie mieli wglądu w logikę aplikacji.
Stało się jasne, że układ fizyczny i logiczny systemu nie był zgodny z zaplanowanym projektem. Wymagana była reprezentacja wizualna, aby wypełnić lukę między kodem a sprzętem.
Zrozumienie schematu wdrożenia 🗺️
Schemat wdrożenia to reprezentacja strukturalna fizycznych artefaktów wdrożonych w systemie. Pokazuje węzły sprzętowe, komponenty oprogramowania działające na nich oraz ścieżki komunikacji między nimi. W przeciwieństwie do schematu sekwencji, który skupia się na czasie i interakcji, schemat wdrożenia skupia się na lokalizacji i łączności.
W tym przypadku schemat spełniał trzy kluczowe funkcje:
- Inwentaryzacja:Wymieniał każdy serwer, kontener i maszynę wirtualną obecnie używane.
- Mapowanie połączeń:Określało, jak dane przepływały między węzłami, w tym typy protokołów.
- Planowanie pojemności:Wskazywało, gdzie zasoby były powielone lub niewystarczające.
Tworzenie tego schematu wymagało udziału wielu stron zaangażowanych. Zespoły operacyjne dostarczyły aktualny stan infrastruktury. Zespoły rozwojowe wyjaśniły, które usługi należały do których węzłów. Zespoły bezpieczeństwa zweryfikowały granice komunikacji.
Komponenty schematu zwykle obejmowały:
- Węzły: Przedstawione jako prostopadłościany, są to urządzenia fizyczne takie jak serwery, routery lub instancje chmury.
- Artefakty: Pliki oprogramowania lub sprzętu wdrażane na węzłach, takie jak pliki wykonywalne lub biblioteki.
- Połączenia: Linie pokazujące ścieżkę komunikacji między węzłami lub artefaktami.
- Interfejsy: Punkty wejścia i wyjścia komunikacji.
Proces mapowania: krok po kroku 🔍
Zespół rozpoczął proces mapowania, zbierając dane surowe. Eksportowali pliki konfiguracyjne z warstwy orchestryzacji i wykonywali zapytania do bazy monitorowania. Te dane zapewniły listę aktywnych instancji i przypisanych do nich ról. Celem było stworzenie „jednego źródła prawdy”, które odpowiadało działającemu środowisku.
Krok 1: Identyfikacja zasobów
Pierwszym zadaniem było zarejestrowanie każdego aktywnego węzła. Obejmowały to serwery produkcyjne, środowiska testowe oraz repliki zapasowe. Zespół odkrył, że kilka starszych serwerów nadal była podłączona do głównego klastra, ale nie otrzymywała ruchu. Zużywały zasoby, nie przynosząc wartości.
Krok 2: Określanie ról węzłów
Każdemu węzłowi przypisano określoną rolę. Niektóre działały jako serwery aplikacji, inne jako węzły baz danych, a niektóre jako balansery obciążenia. Poprzez jasne oznaczenie tych ról zespół mógł zobaczyć, czy jeden węzeł wykonuje zbyt wiele funkcji – częstą przyczynę niestabilności.
Krok 3: Śledzenie ścieżek komunikacji
To był najważniejszy krok. Zespół narysował linie między węzłami, aby przedstawić ruch sieciowy. Zanotowali używane protokoły, takie jak HTTP, TCP lub wewnętrzne kolejki komunikatów. Odkryto poważny problem: kilka usług komunikowała się przez kanały niezaszyfrowane, a niektóre przekazywały dane przez nadmiarowe przeskoków.
Krok 4: Identyfikacja jednostek awaryjnych
Po narysowaniu połączeń diagram ujawnił ryzyka. Konkretny balanser obciążenia był bramą dla 80% ruchu. Jeśli ten węzeł ulegnie awarii, cały system przestanie działać. Na diagramie nie było skonfigurowane żadne zapasowe rozwiązanie.
Faza odkrywania: znalezienie węzła zatorowego 🔧
Po ukończeniu diagramu zespół przeanalizował dane wizualne. Kryzys nie był spowodowany brakiem mocy obliczeniowej, ale błędem konfiguracji sposobu routingu żądań.
Diagram ujawnił, że węzeł bazy danych obsługuje operacje zapisu zarówno dla głównej aplikacji, jak i dla usług raportowania w tle. Usługa raportowania generowała ciężkie zapytania, które blokowały tabele, powodując oczekiwanie głównej aplikacji. Ta zależność nie była zapisana w komentarzach kodu, tylko w układzie wizualnym.
Dodatkowo, diagram pokazał, że serwery aplikacji były skupione w jednym strefie dostępności. Oznaczało to, że awaria zasilania w tej konkretnej strefie spowodowałaby wyłączenie całej usługi. Infrastruktura nie miała dystrybucji geograficznej.
Kluczowe wnioski z analizy:
- Zawieszenie zasobów:Zapisy do bazy danych blokowały odczyty z powodu współdzielenia węzła.
- Opóźnienia sieciowe:Komunikacja między strefami dodawała milisekundy do każdego żądania.
- Luki w redundancji:Nie było żadnych zapasowych balanserów obciążenia.
- Odsunięcie dokumentacji:Działający system nie odpowiadał oryginalnym dokumentom projektowym.
Wizualizacja rozwiązania 🛠️
Po identyfikacji problemów zespół uaktualnił diagram wdrożenia w celu odzwierciedlenia zaproponowanych zmian. Ta uaktualniona wersja stała się projektem przeprowadzania migracji. Nowy projekt zawierał następujące zmiany strukturalne:
- Oddzielenie usług: Usługa raportowania została przeniesiona do dedykowanego węzła bazy danych w celu zapobiegania konfliktom blokowania.
- Rozdzielanie obciążenia: Do punktu wejścia dodano zapasową parę balansujących obciążenie.
- Rozmieszczenie geograficzne: Serwery zostały rozłożone na wielu strefach dostępności.
- Optymalizacja połączeń: Ustanowiono bezpośrednie połączenia dla wymiany danych o wysokiej częstotliwości.
Diagram pozwolił zespołowi symulować nową architekturę przed jej wdrożeniem. Mogli śledzić przebieg żądania przez nowe węzły i zweryfikować, czy nie istniały pętle ani ślepe zakończenia. Ta wizualna weryfikacja zmniejszyła ryzyko błędów wdrożenia.
Porównanie stanów infrastruktury 📊
Poniższa tabela wyróżnia różnice między stanem początkowym a optymalnym stanem wynikającym z analizy diagramu.
| Komponent | Stan początkowy | Stan optymalny | Wpływ |
|---|---|---|---|
| Węzły bazy danych | Współdzielone (Aplikacja + Raporty) | Dedykowane (Aplikacja + Raporty) | Zmniejszone zawieszenie i opóźnienia |
| Balansujące obciążenie | Jeden węzeł | Zapasowa para | Poprawiona dostępność i odporność na awarie |
| Strefy wdrażania | Jedna strefa | Wielostrefowa | Ochrona przed awariami na poziomie strefy |
| Komunikacja | Niezaszyfrowane i pośrednie | Zaszyfrowane i bezpośrednie | Wzmacniana bezpieczeństwo i szybkość |
| Dokumentacja | Ustarełe | Zsynchronizowane z diagramem | Szybsze rozwiązywanie problemów i wdrażanie |
Wdrożenie i weryfikacja ✅
Migracja została wykonana zgodnie z zaktualizowanym diagramem. Zespół najpierw przygotował zmiany w środowisku nieprodukcyjnym. Zweryfikowali, czy nowe połączenia zostały poprawnie utworzone oraz czy ruch był kierowany zgodnie z oczekiwaniami.
Po weryfikacji zmiany zostały wprowadzone w oknie konserwacyjnym. Wdrożenie zostało wykonane etapami, aby zapewnić stabilność. Panele monitoringu zostały uaktualnione w celu śledzenia nowych metryk związanych z węzłami diagramu.
Po wdrożeniu wyniki były natychmiastowe:
- Zmniejszenie opóźnień:Średni czas odpowiedzi spadł o 35%.
- Stosunek błędów:Błędy przekroczenia czasu wykonywania spadły do poziomu zbliżonego do zera.
- Efektywność zasobów:Użycie CPU na węzeł zostało wyrównane, co zmniejszyło koszty.
- Efektywność zespołu:Wdrażanie nowych inżynierów stało się szybsze, ponieważ diagram pełnił rolę przewodnika referencyjnego.
Najlepsze praktyki dotyczące diagramów wdrażania 📝
Aby zapewnić, że diagramy wdrażania pozostają przydatne w czasie, zespół przyjął kilka zasad. Te praktyki pomagają zachować integralność dokumentacji w miarę ewolucji systemu.
1. Przechowuj wersje diagramów
Tak jak kod, diagramy powinny być wersjonowane. Gdy występuje istotna zmiana architektoniczna, powinna zostać utworzona nowa wersja diagramu. Pozwala to zespołom cofnąć się w czasie i zrozumieć, jak system się zmienił.
2. Automatyzuj tam, gdzie to możliwe
Ręczne tworzenie diagramów może prowadzić do błędów. Tam, gdzie to możliwe, diagram powinien być generowany z konfiguracji infrastruktury. Zapewnia to, że reprezentacja wizualna odpowiada rzeczywistemu stanowi.
3. Regularnie przeglądarki
Diagramy szybko się starzeją. Powinna być zaplanowana przeglądarka co kwartał, aby upewnić się, że diagram odpowiada obecnej infrastrukturze. Każda rozbieżność powinna być natychmiast uaktualniona.
4. Uwzględnij szczegóły komunikacji
Węzeł to nie wszystko. Diagram musi pokazywać, jak węzły komunikują się ze sobą. Protokół, numery portów i wymagania dotyczące bezpieczeństwa powinny być zaznaczone na połączeniach.
5. Dokumentuj zależności
Jeśli usługa opiera się na innej, powinno to być jasne na diagramie. Pomaga to w analizie wpływu, gdy usługa jest wycofywana lub aktualizowana.
Techniczne aspekty skalowania 📈
Skalowanie to nie tylko dodawanie więcej serwerów. Chodzi o zarządzanie złożonością wynikającą z rozwoju. Diagram wdrożenia pomaga zarządzać tą złożonością, oferując widok najwyższego poziomu systemu.
Podczas planowania skalowania rozważ następujące czynniki:
- Poziome vs. Pionowe: Określ, czy skalowanie wymaga więcej węzłów, czy bardziej wydajnych węzłów.
- Zarządzanie stanem: Upewnij się, że usługi z pamięcią stanu są odpowiednio rozłożone.
- Przepustowość sieci: Sprawdź, czy sieć może poradzić sobie z wzrostem objętości ruchu.
- Skutki kosztowe: Więcej węzłów oznacza wyższe koszty. Diagram pomaga wizualizować, gdzie można oszczędzić.
W tym konkretnym przypadku decyzja padła na skalowanie poziome. Diagram pokazał, że balansowanie obciążenia było węzłem kluczowym. Dodając więcej węzłów aplikacji i rozprowadzając je między strefami, obciążenie zostało skutecznie rozłożone.
Wyciągnięte lekcje z kryzysu 🎓
Kryzys przyniósł cenne lekcje dla organizacji inżynieryjnej. Wyróżnił znaczenie dokumentacji wizualnej w złożonych systemach.
Widoczność zapobiega ślepym punktom
Gdy nie możesz zobaczyć systemu, nie możesz go naprawić. Diagram ujawnił ukryte zależności, pozwalając zespołowi na ich rozwiązanie przed powstaniem poważnego awarii.
Komunikacja to klucz
Diagram działał jak wspólny język między deweloperami a działem operacyjnym. Usunął niejasności i zapewnił, że wszyscy pracowali na podstawie tego samego zrozumienia infrastruktury.
Dokumentacja to część kodu
Tak jak kod wymaga testowania, dokumentacja wymaga utrzymania. Diagram traktowano jako żywy artefakt, a nie statyczny obraz.
Przygotowanie przewyższa reakcję
Gdyby diagram został stworzony wcześniej, kryzys mógłby zostać uniknięty. Proaktywne planowanie zawsze jest skuteczniejsze niż reaktywne rozwiązywanie problemów.
Ostateczne rozważania na temat wizualizacji architektury 💡
Droga od kryzysu do stabilności była napędzana przejrzystością. Diagram wdrożenia zapewnił tę przejrzystość. Przekształcił chaotyczne środowisko w system strukturalny, który można było zarządzać i skalować.
Dla każdej drużyny zarządzającej systemami rozproszonymi inwestowanie czasu w dokładną dokumentację nie jest stratą. To konieczność. Koszt stworzenia diagramu jest znacznie niższy niż koszt wyładowania systemu.
Wraz z rozwojem systemów rośnie ich złożoność. Prosty diagram nie może już uchwycić każdej szczegółowości, ale zapewnia niezbędną strukturę do poruszania się w tej złożoności. Pozwala zespołom skupić się na istotnych połączeniach, a nie zgubić się w hałasie poszczególnych komponentów.
Przykład pokazuje, że odpowiedni narzędzie, używane poprawnie, może uratować projekt. Diagram wdrożenia był tym narzędziem. Zapewnił mapę potrzebną do poruszania się w labiryncie infrastruktury.
Dla zespołów, które chcą poprawić stabilność infrastruktury, zacznij od zmapowania obecnego stanu. Zidentyfikuj węzły, połączenia i zależności. Gdy masz mapę, droga do optymalizacji staje się jasna.

