











Видимость инфраструктуры часто является разницей между стабильной службой и катастрофическим сбоем. В этом подробном отчете мы исследуем конкретный случай, когда команда столкнулась с серьезными проблемами с задержками и простоем во время события с высокой нагрузкой. Решением не стал новый сервер, ни оптимизация кода, а фундаментальный сдвиг в том, как архитектура визуализировалась и понималась. Построив точную диаграмму развертывания, инженерная команда обнаружила скрытые узкие места и перестроила логику своей инфраструктуры.
В этой статье проводится технический анализ этого процесса. Описывается создание диаграммы, конкретные архитектурные недостатки, обнаруженные в ходе анализа, и последующие улучшения. Здесь нет преувеличений — только механика проектирования систем и практическое применение визуальной документации для решения сложных инженерных задач.
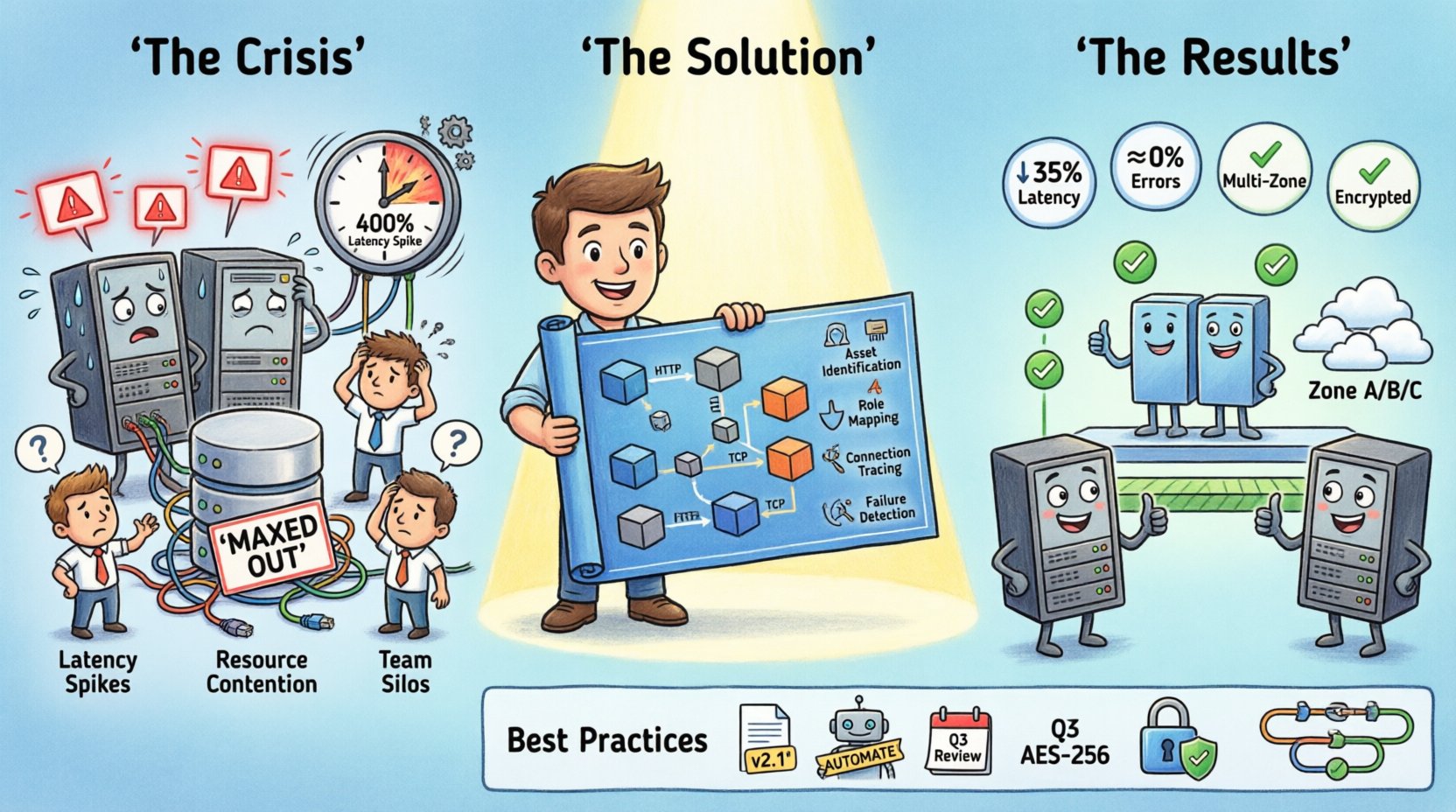
Ситуация: система под давлением 📉
Проект, о котором идет речь, обрабатывал значительный трафик пользователей для цифровой платформы. По мере роста пользовательской базы первоначальная архитектура начала проявлять признаки перегрузки. Команда заметила прерывистые задержки при получении данных и периодические тайм-ауты в часы пик. Стандартные инструменты мониторинга указывали на высокую загрузку ЦП на отдельных узлах, но не объясняли, почему эти узлы находились под стрессом по сравнению с другими.почемуэти узлы находились под стрессом по сравнению с другими.
Без четкой карты инфраструктуры устранение неполадок превратилось в угадывание. Инженеры перезапускали службы, полагая, что это устранит перегрузку, но проблема возвращалась спустя несколько часов. Отсутствие единого представления о топологии развертывания означало, что зависимости между службами часто игнорировались. Протоколы связи предполагались, а не проверялись.
Ключевые признаки кризиса включали:
- Всплески задержек:Время отклика увеличилось на 400% в определенные периоды.
- Конкуренция за ресурсы:Соединения с базой данных были полностью загружены на отдельных шардах.
- Путаница при развертывании:Новый код развертывался в средах, где не были настроены необходимые балансировщики нагрузки.
- Окостенение команд:Разработчики бэкенда не понимали топологию сети, а инженеры по сети не имели представления о логике приложения.
Стало очевидно, что физическая и логическая структура системы не соответствовала намеченной архитектуре. Была необходима визуальная модель, чтобы устранить разрыв между кодом и оборудованием.
Понимание диаграммы развертывания 🗺️
Диаграмма развертывания — это структурное представление физических компонентов, развернутых в системе. Она показывает аппаратные узлы, программные компоненты, работающие на них, и пути коммуникации между ними. В отличие от диаграммы последовательности, которая фокусируется на времени и взаимодействии, диаграмма развертывания фокусируется на расположении и соединении.
В этом кейсе диаграмма выполнила три критически важные функции:
- Инвентаризация:Она перечисляла каждый сервер, контейнер и виртуальную машину, используемую в данный момент.
- Сопоставление соединений:Она определяла, как данные передавались между узлами, включая типы протоколов.
- Планирование пропускной способности:Она выделяла места, где ресурсы были дублированы или недостаточны.
Создание этой диаграммы потребовало участия нескольких заинтересованных сторон. Команды эксплуатации предоставили текущее состояние инфраструктуры. Команды разработки уточнили, какие службы находились на каких узлах. Команды безопасности проверили границы коммуникации.
Компоненты диаграммы обычно включали:
- Узлы: Представленные в виде параллелепипедов, это физические устройства, такие как серверы, маршрутизаторы или облачные экземпляры.
- Артефакты: Программное или аппаратное обеспечение, развернутое на узлах, например, исполняемые файлы или библиотеки.
- Соединители: Линии, показывающие путь коммуникации между узлами или артефактами.
- Интерфейсы: Точки входа и выхода для коммуникации.
Процесс схематизации: пошагово 🔍
Команда начала процесс схематизации, собрав исходные данные. Они экспортировали файлы конфигурации из слоя оркестрации и запросили базу мониторинга. Эти данные предоставили список активных экземпляров и их назначенные роли. Целью было создать «единственный источник правды», соответствующий работающей среде.
Шаг 1: Идентификация активов
Первой задачей стало создание каталога каждого активного узла. К ним относились серверы продакшена, среды тестирования и резервные реплики. Команда обнаружила, что несколько устаревших серверов по-прежнему подключены к основному кластеру, но не получают трафик. Они потребляли ресурсы, не принося при этом пользы.
Шаг 2: Определение ролей узлов
Каждому узлу была присвоена определённая роль. Некоторые выступали в качестве серверов приложений, другие — как узлы баз данных, а некоторые выполняли функции балансировщиков нагрузки. Чёткая маркировка позволила команде увидеть, не выполняет ли один узел слишком много функций — распространённую причину нестабильности.
Шаг 3: Отслеживание путей коммуникации
Это был самый важный шаг. Команда провела линии между узлами, чтобы отобразить сетевой трафик. Они зафиксировали используемые протоколы, такие как HTTP, TCP или внутренние очереди сообщений. Это выявило серьёзную проблему: несколько сервисов обменивались данными по незашифрованным каналам, а некоторые передавали данные через избыточное количество переходов.
Шаг 4: Выявление точек отказа
Как только соединения были нанесены на схему, риски стали очевидными. Определённый балансировщик нагрузки был шлюзом для 80% трафика. Если этот узел выйдет из строя, вся система перестанет работать. На схеме не было настроено резервирование.
Фаза обнаружения: поиск узкого места 🔧
После завершения схемы команда проанализировала визуальные данные. Кризис был вызван не нехваткой вычислительной мощности, а неправильной настройкой маршрутизации запросов.
Схема показала, что узел базы данных обрабатывал операции записи как для основного приложения, так и для фонового сервиса отчётов. Сервис отчётов генерировал тяжёлые запросы, блокировавшие таблицы, из-за чего основное приложение вынуждено было ждать. Эта зависимость не была зафиксирована в комментариях к коду, а только отображена на визуальной схеме.
Кроме того, схема показала, что серверы приложений сконцентрированы в одной зоне доступности. Это означало, что отключение электропитания в этой зоне приведёт к полному отказу сервиса. Инфраструктура не имела географического распределения.
Ключевые выводы анализа:
- Конкуренция за ресурсы:Записи в базу данных блокировали чтение из-за совместного использования узла.
- Задержки в сети:Коммуникация между зонами добавляла миллисекунды к каждому запросу.
- Пробелы в резервировании: Не было резервных балансировщиков нагрузки.
- Отклонение документации: Рабочая система не соответствовала исходным проектным документам.
Визуализация решения 🛠️
Как только проблемы были выявлены, команда обновила диаграмму развертывания, чтобы отразить предложенные изменения. Эта обновленная версия стала чертежом для миграции. Новый дизайн включал следующие структурные изменения:
- Разделение сервисов: Сервис отчетности был перемещен на выделенный узел базы данных, чтобы предотвратить конфликты блокировок.
- Балансировка нагрузки: К точке входа был добавлен резервный набор балансировщиков нагрузки.
- Географическое распределение: Серверы были распределены по нескольким зонам доступности.
- Оптимизация соединений: Были установлены прямые соединения для обмена данными с высокой частотой.
Диаграмма позволила команде смоделировать новую архитектуру до ее внедрения. Они могли отслеживать путь запроса через новые узлы и проверять, что не существовало циклов или тупиковых точек. Такая визуальная проверка снизила риск ошибок при развертывании.
Сравнение состояний инфраструктуры 📊
В следующей таблице выделены различия между начальным состоянием и оптимизированным состоянием, выведенным из анализа диаграммы.
| Компонент | Начальное состояние | Оптимизированное состояние | Влияние |
|---|---|---|---|
| Узлы базы данных | Общие (приложение + отчеты) | Выделенные (приложение + отчеты) | Снижение конкуренции и задержек |
| Балансировщики нагрузки | Один узел | Резервная пара | Улучшенная доступность и отказоустойчивость |
| Зоны развертывания | Одна зона | Множественные зоны | Защита от сбоев на уровне зоны |
| Сообщения | Незашифрованные и косвенные | Зашифрованные и прямые | Улучшенная безопасность и скорость |
| Документация | Устаревший | Синхронизировано с диаграммой | Быстрее устранение неполадок и ввод в работу |
Реализация и проверка ✅
Переезд прошел в соответствии с обновленной диаграммой. Сначала команда подготовила изменения в среде, не предназначенной для производства. Они проверили, что новые соединения были установлены правильно, и что трафик направлялся так, как ожидалось.
После проверки изменения были внедрены во время планового окна обслуживания. Развертывание выполнялось поэтапно для обеспечения стабильности. Панели мониторинга были обновлены для отслеживания новых метрик, связанных с узлами диаграммы.
После внедрения результаты были мгновенными:
- Снижение задержки: Среднее время отклика снизилось на 35%.
- Уровень ошибок: Ошибки превышения времени ожидания снизились до почти нуля.
- Эффективность использования ресурсов: Использование ЦП на узле стало нормальным, что снизило затраты.
- Эффективность команды: Ввод новых инженеров стал быстрее, поскольку диаграмма служила справочным руководством.
Лучшие практики для диаграмм развертывания 📝
Чтобы обеспечить, что диаграммы развертывания остаются полезными с течением времени, команда приняла несколько руководящих принципов. Эти практики помогают сохранить целостность документации по мере развития системы.
1. Храните диаграммы с версиями
Как и код, диаграммы должны быть версионированы. При значительных изменениях архитектуры должна создаваться новая версия диаграммы. Это позволяет командам возвращаться к прошлому и понимать, как развивалась система.
2. Автоматизируйте, где возможно
Ручное создание диаграмм может привести к ошибкам. Там, где это возможно, диаграмма должна генерироваться из конфигурации инфраструктуры. Это гарантирует, что визуальное представление соответствует реальному состоянию.
3. Регулярно проводите обзор
Диаграммы быстро устаревают. Должна быть запланирована ежеквартальная проверка, чтобы убедиться, что диаграмма соответствует текущей инфраструктуре. Любые расхождения должны быть немедленно исправлены.
4. Включайте сведения о коммуникации
Один узел недостаточен. Диаграмма должна показывать, как узлы общаются между собой. На соединениях должны быть указаны протокол, номера портов и требования к безопасности.
5. Документируйте зависимости
Если сервис зависит от другого, это должно быть очевидно на диаграмме. Это помогает при анализе последствий, когда сервис устаревает или обновляется.
Технические аспекты масштабирования 📈
Масштабирование — это не просто добавление дополнительных серверов. Речь идет о управлении сложностью, возникающей при росте. Диаграмма развертывания помогает управлять этой сложностью, предоставляя общий обзор системы.
При планировании масштабирования учитывайте следующие факторы:
- Горизонтальное и вертикальное масштабирование:Определите, требуется ли масштабирование за счет увеличения количества узлов или за счет более мощных узлов.
- Управление состоянием:Убедитесь, что службы с состоянием правильно распределены.
- Пропускная способность сети:Проверьте, может ли сеть справиться с увеличением объема трафика.
- Финансовые последствия:Больше узлов означает более высокие затраты. Диаграмма помогает визуализировать, где можно сэкономить.
В данном конкретном случае было принято решение масштабироваться горизонтально. Диаграмма показала, что балансировщик нагрузки является узким местом. Добавив больше узлов приложения и распределив их по зонам, нагрузка была эффективно распределена.
Уроки, извлеченные из кризиса 🎓
Кризис дал ценные уроки для инженерной организации. Он подчеркнул важность визуальной документации в сложных системах.
Видимость предотвращает слепые зоны
Когда вы не видите систему, вы не можете её исправить. Диаграмма сделала скрытые зависимости видимыми, позволив команде устранить их до того, как они вызвали серьезный сбой.
Коммуникация — это ключ
Диаграмма выступила общим языком между разработчиками и операционной командой. Она устранила неоднозначность и обеспечила, чтобы все работали с одинаковым пониманием инфраструктуры.
Документация — это часть кода
Так же, как код требует тестирования, документация требует поддержки. Диаграмму рассматривали как живой артефакт, а не как статическое изображение.
Подготовка превосходит реакцию
Если бы диаграмма была создана раньше, кризис, возможно, был бы избежан. Прогнозное планирование всегда эффективнее, чем реактивное устранение неполадок.
Заключительные мысли о визуализации архитектуры 💡
Путь от кризиса к стабильности был обусловлен ясностью. Диаграмма развертывания обеспечила эту ясность. Она превратила хаотическую среду в структурированную систему, которую можно было управлять и масштабировать.
Для любой команды, управляющей распределенными системами, затраты времени на точную документацию — не расточительство. Это необходимость. Стоимость создания диаграммы намного ниже стоимости простоев.
По мере роста систем сложность возрастает. Простая диаграмма уже не может захватить все детали, но она предоставляет необходимую основу для навигации в этой сложности. Она позволяет командам сосредоточиться на важных связях, а не теряться в шуме отдельных компонентов.
Кейс показывает, что правильный инструмент, правильно примененный, может спасти проект. Диаграмма развертывания и была этим инструментом. Она предоставила карту, необходимую для навигации по лабиринту инфраструктуры.
Для команд, стремящихся улучшить стабильность своей инфраструктуры, начните с составления карты текущего состояния. Определите узлы, соединения и зависимости. Как только у вас будет карта, путь к оптимизации станет очевидным.

