











La visibilité de l’infrastructure est souvent la différence entre un service stable et une panne catastrophique. Dans ce compte rendu détaillé, nous explorons un scénario précis où une équipe a fait face à des problèmes de latence sévères et à des interruptions pendant un événement à fort trafic. La solution n’était ni un nouveau serveur, ni une optimisation du code, mais un changement fondamental dans la manière dont l’architecture était visualisée et comprise. En construisant un diagramme de déploiement précis, l’équipe d’ingénierie a identifié des goulets d’étranglement cachés et restructuré la logique de son infrastructure.
Cet article constitue une analyse technique de ce processus. Il détaille la création du diagramme, les défauts architecturaux spécifiques découverts, ainsi que les améliorations ultérieures. Il n’y a ici aucune hype, seulement les mécanismes de conception de systèmes et l’application concrète de la documentation visuelle pour résoudre des problèmes d’ingénierie complexes.
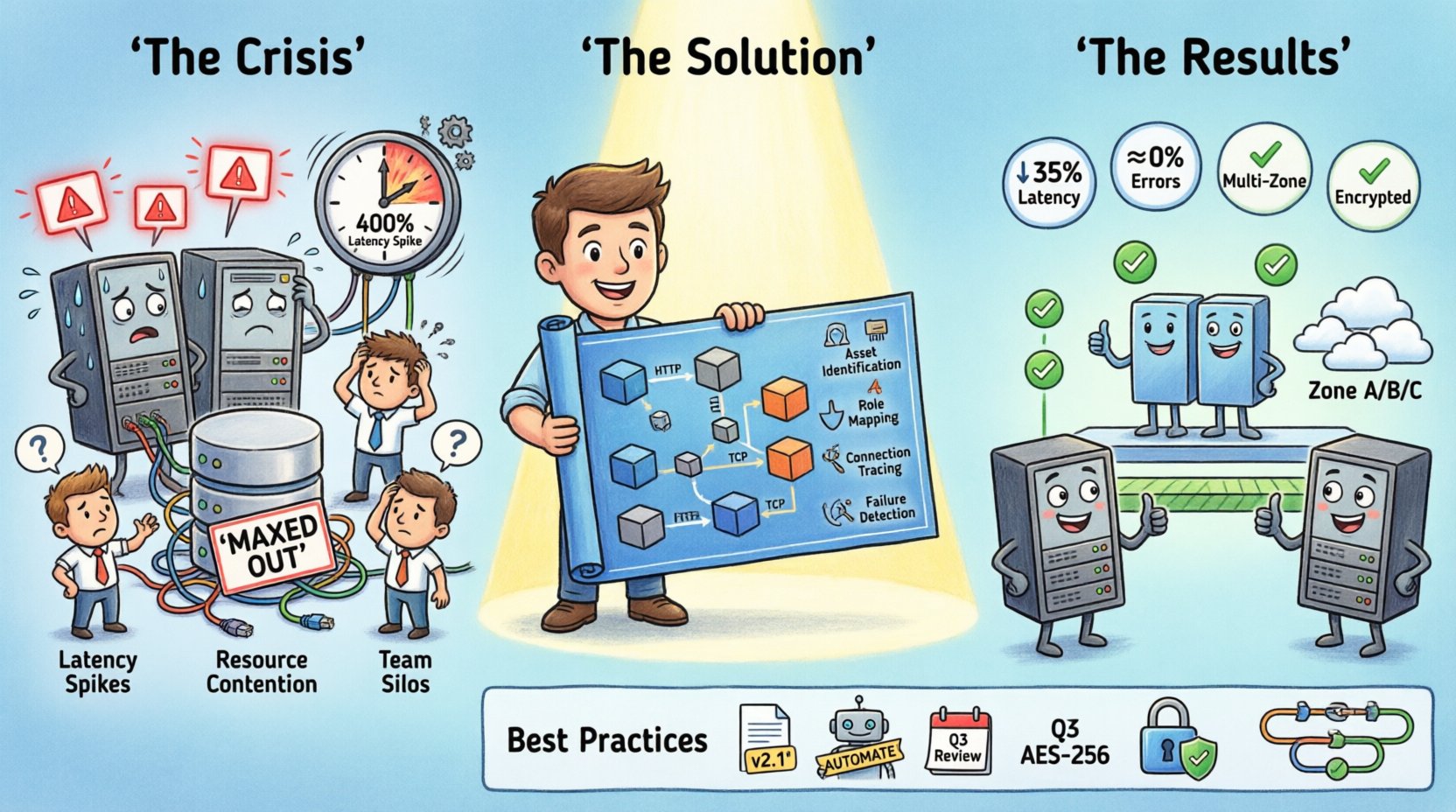
La situation : Un système sous pression 📉
Le projet en question gère un volume important de trafic utilisateur pour une plateforme numérique. Au fur et à mesure que la base d’utilisateurs grandissait, l’architecture initiale commençait à montrer des signes de fatigue. L’équipe a remarqué des délais intermittents dans la récupération des données et des timeouts occasionnels pendant les heures de pointe. Les outils de surveillance standards indiquaient une utilisation élevée du CPU sur certains nœuds, mais ils ne permettaient pas d’expliquerpourquoices nœuds étaient sous pression par rapport aux autres.
Sans une carte claire de l’infrastructure, le dépannage est devenu un jeu de devinettes. Les ingénieurs redémarraient des services, en croyant que cela éliminerait la congestion, mais le problème réapparaissait des heures plus tard. Le manque d’une vue unifiée de la topologie de déploiement signifiait que les dépendances entre les services étaient souvent ignorées. Les protocoles de communication étaient supposés plutôt que vérifiés.
Les indicateurs clés de la crise incluaient :
- Pic de latence :Les temps de réponse ont augmenté de 400 % pendant des fenêtres spécifiques.
- Contestation des ressources :Les connexions à la base de données étaient saturées sur des segments spécifiques.
- Confusion dans le déploiement :Du nouveau code était déployé dans des environnements qui ne disposaient pas des équilibreurs de charge nécessaires configurés.
- Cloisonnement des équipes :Les développeurs backend ne comprenaient pas la topologie du réseau, et les ingénieurs réseau manquaient de compréhension de la logique de l’application.
Il est devenu clair que la disposition physique et logique du système ne correspondait pas au design prévu. Une représentation visuelle était nécessaire pour combler le fossé entre le code et le matériel.
Comprendre le diagramme de déploiement 🗺️
Un diagramme de déploiement est une représentation structurelle des artefacts physiques déployés dans un système. Il montre les nœuds matériels, les composants logiciels qui s’exécutent dessus, et les chemins de communication entre eux. Contrairement à un diagramme de séquence, qui se concentre sur le temps et les interactions, un diagramme de déploiement se concentre sur la localisation et la connectivité.
Pour cette étude de cas, le diagramme a rempli trois fonctions essentielles :
- Inventaire :Il listait chaque serveur, conteneur et machine virtuelle actuellement en usage.
- Cartographie des connexions :Il définissait comment les données circulaient entre les nœuds, y compris les types de protocoles.
- Planification de la capacité :Il mettait en évidence où les ressources étaient redondantes ou insuffisantes.
La création de ce diagramme a nécessité l’apport de plusieurs parties prenantes. Les équipes opérationnelles ont fourni l’état actuel de l’infrastructure. Les équipes de développement ont clarifié quelles services appartenaient à quels nœuds. Les équipes sécurité ont vérifié les limites de communication.
Les composants du diagramme incluaient généralement :
- Nœuds : Représentés sous forme de cuboïdes, ce sont des dispositifs physiques tels que des serveurs, des routeurs ou des instances cloud.
- Artifacts : Les fichiers logiciels ou matériels déployés sur les nœuds, tels que des exécutables ou des bibliothèques.
- Connecteurs : Des lignes indiquant le chemin de communication entre les nœuds ou les artefacts.
- Interfaces : Les points d’entrée et de sortie pour la communication.
Le processus de cartographie : étape par étape 🔍
L’équipe a commencé le processus de cartographie en rassemblant des données brutes. Elle a exporté les fichiers de configuration depuis la couche d’orchestration et interrogé la base de données de supervision. Ces données ont fourni une liste des instances actives et de leurs rôles attribués. L’objectif était de créer une « source unique de vérité » correspondant à l’environnement en cours d’exécution.
Étape 1 : Identification des actifs
La première tâche consistait à cataloguer chaque nœud actif. Cela incluait les serveurs de production, les environnements de préproduction et les réplicas de sauvegarde. L’équipe a découvert que plusieurs serveurs hérités étaient encore connectés au cluster principal, mais ne recevaient pas de trafic. Ils consommaient des ressources sans apporter de valeur.
Étape 2 : Définition des rôles des nœuds
Chaque nœud a été attribué à un rôle spécifique. Certains agissaient comme serveurs d’applications, d’autres comme nœuds de base de données, et certains servaient de chargeurs d’équilibre. En les étiquetant clairement, l’équipe pouvait voir si un seul nœud effectuait trop de fonctions, une cause fréquente d’instabilité.
Étape 3 : Suivi des chemins de communication
C’était l’étape la plus critique. L’équipe a tracé des lignes entre les nœuds pour représenter le trafic réseau. Ils ont noté les protocoles utilisés, tels que HTTP, TCP ou des files de messages internes. Cela a révélé un problème majeur : plusieurs services communiquaient sur des canaux non chiffrés, et certains traversaient des sauts multiples de manière inutile.
Étape 4 : Identification des points de défaillance uniques
Une fois les connexions tracées, le diagramme a rendu les risques visibles. Un équilibreur de charge spécifique était la passerelle pour 80 % du trafic. Si ce nœud échouait, tout le système tombait. Aucune redondance n’était configurée sur le diagramme.
La phase de découverte : localisation du goulot d’étranglement 🔧
Avec le diagramme terminé, l’équipe a analysé les données visuelles. La crise n’était pas due à un manque de puissance de traitement, mais à une mauvaise configuration du routage des requêtes.
Le diagramme a révélé qu’un nœud de base de données traitait les opérations d’écriture pour l’application principale et un service de rapport en arrière-plan. Le service de rapport générait des requêtes lourdes qui verrouillaient les tables, faisant attendre l’application principale. Cette dépendance n’était pas documentée dans les commentaires de code, mais uniquement dans la disposition visuelle.
En outre, le diagramme montrait que les serveurs d’applications étaient regroupés dans une seule zone de disponibilité. Cela signifiait qu’une panne de courant dans cette zone spécifique ferait tomber l’ensemble du service. L’infrastructure manquait de distribution géographique.
Principaux résultats de l’analyse :
- Contestation des ressources :Les écritures sur la base de données bloquaient les lectures en raison de l’utilisation partagée du nœud.
- Latence réseau :La communication entre zones ajoutait des millisecondes à chaque requête.
- Manques de redondance : Aucun équilibreur de charge de secours n’était présent.
- Dérive de la documentation : Le système en cours d’exécution ne correspondait pas aux documents de conception d’origine.
Visualisation de la solution 🛠️
Une fois les problèmes identifiés, l’équipe a mis à jour le diagramme de déploiement pour refléter les modifications proposées. Cette version mise à jour est devenue le plan directeur pour la migration. La nouvelle conception incluait les modifications structurelles suivantes :
- Séparation des services : Le service de reporting a été déplacé vers un nœud de base de données dédié afin d’éviter les conflits de verrouillage.
- Équilibrage de charge : Une paire redondante d’équilibreurs de charge a été ajoutée au point d’entrée.
- Répartition géographique : Les serveurs ont été répartis sur plusieurs zones de disponibilité.
- Optimisation des connexions : Des connexions directes ont été établies pour les échanges de données à haute fréquence.
Le diagramme a permis à l’équipe de simuler la nouvelle architecture avant de la mettre en œuvre. Ils pouvaient suivre le parcours d’une requête à travers les nouveaux nœuds et vérifier qu’aucune boucle ni impasse n’existait. Cette validation visuelle a réduit le risque d’erreurs de déploiement.
Comparaison des états de l’infrastructure 📊
Le tableau suivant met en évidence les différences entre l’état initial et l’état optimisé dérivé de l’analyse du diagramme.
| Composant | État initial | État optimisé | Impact |
|---|---|---|---|
| Nœuds de base de données | Partagé (App + Rapports) | Dédier (App + Rapports) | Réduction de la contention et de la latence |
| Équilibreurs de charge | Nœud unique | Paire redondante | Amélioration de la disponibilité et de la tolérance aux pannes |
| Zones de déploiement | Zone unique | Multi-zone | Protection contre les défaillances au niveau de la zone |
| Communication | Non chiffré et indirect | Chiffré et direct | Sécurité et vitesse améliorées |
| Documentation | Obsolète | Synchronisé avec le diagramme | Dépannage et intégration plus rapides |
Mise en œuvre et validation ✅
La migration a suivi étroitement le diagramme mis à jour. L’équipe a d’abord mis en place les modifications dans un environnement non productif. Elle a validé que les nouvelles connexions étaient établies correctement et que le trafic était acheminé comme prévu.
Une fois validées, les modifications ont été déployées pendant une fenêtre de maintenance. Le déploiement a été effectué par étapes pour assurer la stabilité. Les tableaux de bord de surveillance ont été mis à jour pour suivre les nouvelles métriques associées aux nœuds du diagramme.
Après mise en œuvre, les résultats ont été immédiats :
- Réduction de la latence :Le temps de réponse moyen a diminué de 35 %.
- Taux d’erreurs :Les erreurs de délai d’attente ont chuté presque à zéro.
- Efficacité des ressources :L’utilisation du CPU par nœud s’est normalisée, réduisant ainsi les coûts.
- Efficacité de l’équipe :L’intégration des nouveaux ingénieurs s’est accélérée car le diagramme servait de guide de référence.
Meilleures pratiques pour les diagrammes de déploiement 📝
Pour garantir que les diagrammes de déploiement restent utiles au fil du temps, l’équipe a adopté plusieurs directives. Ces pratiques aident à préserver l’intégrité de la documentation au fur et à mesure que le système évolue.
1. Conserver les diagrammes versionnés
Tout comme le code, les diagrammes doivent être versionnés. Lorsqu’une modification architecturale importante a lieu, une nouvelle version du diagramme doit être créée. Cela permet aux équipes de remonter dans le temps et de comprendre comment le système a évolué.
2. Automatiser autant que possible
La création manuelle de diagrammes peut entraîner des erreurs. Là où les outils le permettent, le diagramme doit être généré à partir de la configuration de l’infrastructure. Cela garantit que la représentation visuelle correspond à l’état réel.
3. Réviser régulièrement
Les diagrammes deviennent rapidement obsolètes. Une revue trimestrielle doit être planifiée pour s’assurer que le diagramme correspond à l’infrastructure actuelle. Toute divergence doit être corrigée immédiatement.
4. Inclure les détails de communication
Un nœud ne suffit pas. Le diagramme doit montrer comment les nœuds communiquent entre eux. Le protocole, les numéros de port et les exigences de sécurité doivent être indiqués sur les connecteurs.
5. Documenter les dépendances
Si un service dépend d’un autre, cela doit être clair sur le diagramme. Cela aide à l’analyse des impacts lorsqu’un service est déprécié ou mis à jour.
Considérations techniques pour le dimensionnement 📈
Le dimensionnement ne consiste pas seulement à ajouter plus de serveurs. Il s’agit de gérer la complexité qui découle de la croissance. Un diagramme de déploiement aide à gérer cette complexité en offrant une vue d’ensemble du système.
Lors de la planification du dimensionnement, considérez les facteurs suivants :
- Horizontal versus vertical : Déterminez si le dimensionnement nécessite plus de nœuds ou des nœuds plus puissants.
- Gestion de l’état : Assurez-vous que les services étatiques sont correctement répartis.
- Bande passante du réseau : Vérifiez si le réseau peut supporter le volume accru de trafic.
- Implications coûts : Plus de nœuds signifient des coûts plus élevés. Le diagramme aide à visualiser où des économies peuvent être réalisées.
Dans ce cas particulier, la décision a été de dimensionner horizontalement. Le diagramme a montré que le chargeur d’équilibre était le goulot d’étranglement. En ajoutant plus de nœuds d’application et en les répartissant sur plusieurs zones, la charge a été efficacement partagée.
Leçons tirées de la crise 🎓
La crise a fourni des leçons précieuses pour l’organisation ingénierie. Elle a mis en évidence l’importance de la documentation visuelle dans les systèmes complexes.
La visibilité évite les points aveugles
Quand vous ne pouvez pas voir le système, vous ne pouvez pas le corriger. Le diagramme a rendu visibles les dépendances cachées, permettant à l’équipe de les traiter avant qu’elles ne provoquent une panne majeure.
La communication est essentielle
Le diagramme a agi comme un langage commun entre les développeurs et les opérations. Il a éliminé toute ambiguïté et assuré que tout le monde travaillait à partir de la même compréhension de l’infrastructure.
La documentation fait partie du code
Tout comme le code a besoin d’être testé, la documentation a besoin d’être maintenue. Le diagramme a été traité comme un artefact vivant, et non comme une image statique.
La préparation bat la réaction
Si le diagramme avait été créé plus tôt, la crise aurait pu être évitée. La planification proactive est toujours plus efficace que le dépannage réactif.
Réflexions finales sur la visualisation de l’architecture 💡
Le parcours de la crise à la stabilité a été guidé par la clarté. Le diagramme de déploiement a fourni cette clarté. Il a transformé un environnement chaotique en un système structuré pouvant être géré et dimensionné.
Pour toute équipe gérant des systèmes distribués, investir du temps dans une documentation précise n’est pas une perte de temps. C’est une nécessité. Le coût de création d’un diagramme est bien inférieur au coût d’un événement d’indisponibilité.
À mesure que les systèmes grandissent, la complexité augmente. Un diagramme simple ne peut plus capturer chaque détail, mais il fournit le cadre essentiel nécessaire pour naviguer dans cette complexité. Il permet aux équipes de se concentrer sur les connexions importantes plutôt que de s’égarer dans le bruit des composants individuels.
L’étude de cas démontre que l’outil approprié, utilisé correctement, peut sauver un projet. Le diagramme de déploiement était cet outil. Il a fourni la carte nécessaire pour naviguer dans le labyrinthe de l’infrastructure.
Pour les équipes souhaitant améliorer la stabilité de leur infrastructure, commencez par cartographier votre état actuel. Identifiez les nœuds, les connexions et les dépendances. Une fois que vous avez la carte, le chemin vers l’optimisation devient clair.

