











La visibilidad de la infraestructura a menudo marca la diferencia entre un servicio estable y una falla catastrófica. En este relato detallado, exploramos un escenario específico en el que un equipo enfrentó problemas graves de latencia y tiempo de inactividad durante un evento de alta tráfico. La solución no fue un nuevo servidor ni una optimización de código, sino un cambio fundamental en la forma en que la arquitectura se visualizaba y comprendía. Al construir un diagrama de despliegue preciso, el equipo de ingeniería identificó cuellos de botella ocultos y reestructuró la lógica de su infraestructura.
Este artículo sirve como un análisis técnico de ese proceso. Detalla la creación del diagrama, los defectos arquitectónicos específicos descubiertos y las mejoras posteriores. No hay exageraciones aquí, solo los mecanismos del diseño de sistemas y la aplicación práctica de la documentación visual para resolver problemas de ingeniería complejos.
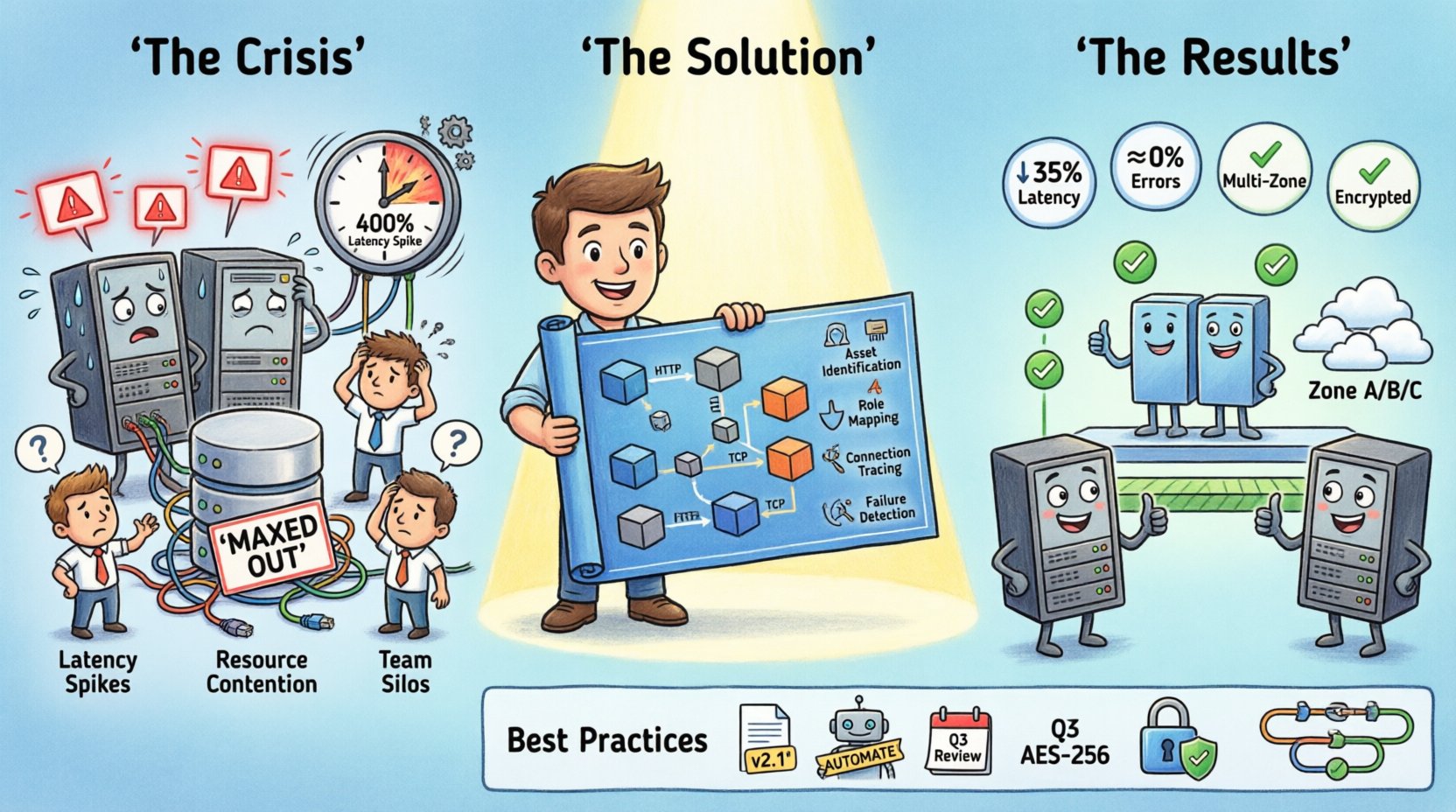
La situación: Un sistema bajo presión 📉
El proyecto en cuestión manejaba una tráfico de usuarios significativo para una plataforma digital. A medida que crecía la base de usuarios, la arquitectura inicial comenzó a mostrar signos de estrés. El equipo notó retrasos intermitentes en la recuperación de datos y tiempos de espera ocasionales durante las horas pico. Las herramientas estándar de monitoreo indicaron un uso elevado de la CPU en nodos específicos, pero no explicaronpor quéesos nodos estaban bajo estrés en comparación con otros.
Sin un mapa claro de la infraestructura, el diagnóstico se convirtió en un juego de adivinanzas. Los ingenieros reiniciaban servicios, creyendo que eso aliviaría la congestión, solo para que el problema reapareciera horas después. La falta de una vista unificada de la topología de despliegue significaba que las dependencias entre servicios a menudo se pasaban por alto. Los protocolos de comunicación se asumían en lugar de verificarse.
Los indicadores clave de la crisis incluyeron:
- Picos de latencia:Los tiempos de respuesta aumentaron un 400% durante ventanas específicas.
- Contención de recursos:Las conexiones a la base de datos alcanzaron su límite máximo en fragmentos específicos.
- Confusión en el despliegue:Se estaba desplegando nuevo código en entornos que carecían de equilibradores de carga configurados.
- Fosas entre equipos:Los desarrolladores de backend no entendían la topología de red, y los ingenieros de red carecían de visión sobre la lógica de la aplicación.
Quedó claro que la disposición física y lógica del sistema no estaba alineada con el diseño previsto. Se necesitaba una representación visual para cerrar la brecha entre el código y el hardware.
Comprendiendo el diagrama de despliegue 🗺️
Un diagrama de despliegue es una representación estructural de los artefactos físicos desplegados en un sistema. Muestra los nodos de hardware, los componentes de software que se ejecutan en ellos y las rutas de comunicación entre ellos. A diferencia de un diagrama de secuencia, que se centra en el tiempo e interacción, un diagrama de despliegue se enfoca en la ubicación y conectividad.
Para este estudio de caso, el diagrama cumplió tres propósitos críticos:
- Inventario:Enumeró cada servidor, contenedor y máquina virtual actualmente en uso.
- Mapa de conexiones:Definió cómo fluía los datos entre nodos, incluyendo los tipos de protocolo.
- Planificación de capacidad:Destacó dónde los recursos estaban duplicados o insuficientes.
Crear este diagrama requirió la aportación de múltiples partes interesadas. Los equipos de operaciones proporcionaron el estado actual de la infraestructura. Los equipos de desarrollo aclararon qué servicios pertenecían a qué nodos. Los equipos de seguridad verificaron los límites de comunicación.
Los componentes del diagrama incluían típicamente:
- Nodos: Representados como cuboides, estos son dispositivos físicos como servidores, routers o instancias en la nube.
- Artefactos: Los archivos de software o hardware desplegados en los nodos, como ejecutables o bibliotecas.
- Conectores: Líneas que muestran la ruta de comunicación entre nodos o artefactos.
- Interfaces: Los puntos de entrada y salida para la comunicación.
El proceso de mapeo: Paso a paso 🔍
El equipo comenzó el proceso de mapeo recopilando datos brutos. Exportaron archivos de configuración desde la capa de orquestación y consultaron la base de datos de monitoreo. Estos datos proporcionaron una lista de instancias activas y sus roles asignados. El objetivo era crear una “única fuente de verdad” que coincidiera con el entorno en ejecución.
Paso 1: Identificación de activos
La primera tarea fue catalogar cada nodo activo. Esto incluía servidores de producción, entornos de pruebas y réplicas de respaldo. El equipo descubrió que varios servidores heredados aún estaban conectados al clúster principal, pero no recibían tráfico. Estos estaban consumiendo recursos sin aportar valor.
Paso 2: Definición de roles de nodos
Cada nodo fue asignado a un rol específico. Algunos actuaban como servidores de aplicaciones, otros como nodos de base de datos y algunos servían como equilibradores de carga. Al etiquetarlos claramente, el equipo pudo ver si un solo nodo estaba realizando demasiadas funciones, una causa común de inestabilidad.
Paso 3: Rastreo de rutas de comunicación
Este fue el paso más crítico. El equipo dibujó líneas entre nodos para representar el tráfico de red. Anotaron los protocolos utilizados, como HTTP, TCP o colas de mensajería internas. Esto reveló un problema importante: varias servicios estaban comunicándose a través de canales no cifrados, y algunos estaban atravesando múltiples saltos innecesariamente.
Paso 4: Identificación de puntos únicos de fallo
Una vez dibujadas las conexiones, el diagrama hizo visible los riesgos. Un equilibrador de carga específico era la puerta de entrada para el 80 % del tráfico. Si ese nodo fallaba, todo el sistema se caía. No había redundancia configurada en el diagrama.
La fase de descubrimiento: Encontrar el cuello de botella 🔧
Con el diagrama completo, el equipo analizó los datos visuales. La crisis no fue causada por la falta de potencia de procesamiento, sino por una mala configuración en cómo se enrutaban las solicitudes.
El diagrama reveló que un nodo de base de datos estaba manejando operaciones de escritura para la aplicación principal y un servicio de informes en segundo plano. El servicio de informes generaba consultas pesadas que bloqueaban tablas, haciendo que la aplicación principal esperara. Esta dependencia no estaba documentada en los comentarios del código, sino solo en la disposición visual.
Además, el diagrama mostró que los servidores de aplicaciones estaban agrupados en una única zona de disponibilidad. Esto significaba que una interrupción de energía en esa zona específica haría caer todo el servicio. La infraestructura carecía de distribución geográfica.
Hallazgos clave del análisis:
- Contención de recursos:Las escrituras en la base de datos bloqueaban las lecturas debido al uso compartido del nodo.
- Latencia de red:La comunicación entre zonas añadía milisegundos a cada solicitud.
- Fallas en redundancia:No había equilibradores de carga de respaldo.
- Desviación de documentación:El sistema en ejecución no coincidía con los documentos de diseño originales.
Visualizando la solución 🛠️
Una vez identificados los problemas, el equipo actualizó el diagrama de despliegue para reflejar los cambios propuestos. Esta versión actualizada se convirtió en el plano maestro para la migración. El nuevo diseño incluyó los siguientes cambios estructurales:
- Separación de servicios: El servicio de informes se movió a un nodo de base de datos dedicado para evitar conflictos de bloqueo.
- Equilibrio de carga: Se agregó un par redundante de equilibradores de carga al punto de entrada.
- Distribución geográfica: Los servidores se distribuyeron a través de múltiples zonas de disponibilidad.
- Optimización de conexiones: Se establecieron conexiones directas para intercambios de datos de alta frecuencia.
El diagrama permitió al equipo simular la nueva arquitectura antes de implementarla. Podían rastrear el recorrido de una solicitud a través de los nuevos nodos y verificar que no existieran bucles ni puntos muertos. Esta validación visual redujo el riesgo de errores en el despliegue.
Comparación de los estados de la infraestructura 📊
La siguiente tabla destaca las diferencias entre el estado inicial y el estado optimizado derivado del análisis del diagrama.
| Componente | Estado inicial | Estado optimizado | Impacto |
|---|---|---|---|
| Nodos de base de datos | Compartido (Aplicación + Informes) | Dedicado (Aplicación + Informes) | Reducción de contención y latencia |
| Equilibradores de carga | Nodo único | Par redundante | Mejor disponibilidad y tolerancia a fallos |
| Zonas de despliegue | Zona única | Multi-zona | Protección contra fallos a nivel de zona |
| Comunicación | No cifrado e indirecto | Cifrado y directo | Seguridad y velocidad mejoradas |
| Documentación | Obsoleto | Sincronizado con el diagrama | Resolución de problemas y incorporación más rápida |
Implementación y validación ✅
La migración siguió de cerca el diagrama actualizado. El equipo preparó los cambios en un entorno no productivo primero. Validaron que las nuevas conexiones se establecieron correctamente y que el tráfico se estaba redirigiendo según lo esperado.
Una vez validados, los cambios se implementaron durante una ventana de mantenimiento. La implementación se ejecutó en fases para garantizar la estabilidad. Los paneles de monitoreo se actualizaron para rastrear las nuevas métricas asociadas con los nodos del diagrama.
Después de la implementación, los resultados fueron inmediatos:
- Reducción de latencia:El tiempo promedio de respuesta disminuyó un 35%.
- Tasa de errores:Los errores de tiempo de espera disminuyeron hasta casi cero.
- Eficiencia de recursos:El uso de CPU por nodo se normalizó, reduciendo los costos.
- Eficiencia del equipo:La incorporación de nuevos ingenieros se volvió más rápida ya que el diagrama sirvió como guía de referencia.
Mejores prácticas para diagramas de despliegue 📝
Para garantizar que los diagramas de despliegue sigan siendo útiles con el tiempo, el equipo adoptó varias directrices. Estas prácticas ayudan a mantener la integridad de la documentación a medida que evoluciona el sistema.
1. Mantenga los diagramas versionados
Al igual que el código, los diagramas deben ser versionados. Cuando ocurre un cambio arquitectónico significativo, se debe crear una nueva versión del diagrama. Esto permite a los equipos revisar y comprender cómo evolucionó el sistema.
2. Automatice cuando sea posible
El dibujo manual de diagramas puede generar errores. Donde las herramientas lo permitan, el diagrama debe generarse a partir de la configuración de la infraestructura. Esto garantiza que la representación visual coincida con el estado real.
3. Revise con regularidad
Los diagramas se vuelven obsoletos rápidamente. Debe programarse una revisión trimestral para asegurarse de que el diagrama coincida con la infraestructura actual. Cualquier discrepancia debe actualizarse de inmediato.
4. Incluya detalles de comunicación
Un nodo no es suficiente. El diagrama debe mostrar cómo los nodos se comunican entre sí. El protocolo, los números de puerto y los requisitos de seguridad deben indicarse en los conectores.
5. Documente las dependencias
Si un servicio depende de otro, esto debe quedar claro en el diagrama. Esto ayuda en el análisis de impacto cuando un servicio se elimina o se actualiza.
Consideraciones técnicas para la escalabilidad 📈
Escalabilidad no se trata solo de agregar más servidores. Se trata de gestionar la complejidad que conlleva el crecimiento. Un diagrama de despliegue ayuda a gestionar esta complejidad al proporcionar una vista de alto nivel del sistema.
Al planificar la escalabilidad, considere los siguientes factores:
- Horizontal frente a vertical:Determine si la escalabilidad requiere más nodos o nodos más potentes.
- Gestión del estado:Asegúrese de que los servicios con estado se distribuyan correctamente.
- Ancho de banda de red:Verifique si la red puede manejar el aumento del volumen de tráfico.
- Implicaciones de costo:Más nodos significan mayores costos. El diagrama ayuda a visualizar dónde se pueden realizar ahorros.
En este caso específico, la decisión fue escalar horizontalmente. El diagrama mostró que el balanceador de carga era el cuello de botella. Al agregar más nodos de aplicación y distribuirlos entre zonas, la carga se compartió de forma efectiva.
Lecciones aprendidas desde la crisis 🎓
La crisis proporcionó lecciones valiosas para la organización de ingeniería. Destacó la importancia de la documentación visual en sistemas complejos.
La visibilidad evita puntos ciegos
Cuando no puedes ver el sistema, no puedes arreglarlo. El diagrama hizo visibles las dependencias ocultas, permitiendo al equipo abordarlas antes de que causaran una falla importante.
La comunicación es clave
El diagrama actuó como un lenguaje común entre desarrolladores y operaciones. Eliminó la ambigüedad y aseguró que todos trabajaran con la misma comprensión de la infraestructura.
La documentación forma parte del código
Al igual que el código necesita pruebas, la documentación necesita mantenimiento. El diagrama se trató como un artefacto vivo, no como una imagen estática.
La preparación supera la reacción
Si el diagrama hubiera sido creado antes, la crisis podría haberse evitado. La planificación proactiva siempre es más efectiva que la resolución reactiva de problemas.
Reflexiones finales sobre la visualización de arquitectura 💡
El camino desde la crisis hasta la estabilidad fue impulsado por la claridad. El diagrama de despliegue proporcionó esa claridad. Transformó un entorno caótico en un sistema estructurado que podía gestionarse y escalarse.
Para cualquier equipo que gestione sistemas distribuidos, invertir tiempo en una documentación precisa no es una pérdida de tiempo. Es una necesidad. El costo de crear un diagrama es mucho menor que el costo de un evento de inactividad.
A medida que los sistemas crecen, la complejidad aumenta. Un diagrama simple ya no puede capturar todos los detalles, pero proporciona el marco esencial necesario para navegar esa complejidad. Permite a los equipos centrarse en las conexiones importantes en lugar de perderse en el ruido de los componentes individuales.
El estudio de caso demuestra que la herramienta adecuada, utilizada correctamente, puede salvar un proyecto. El diagrama de despliegue fue esa herramienta. Proporcionó el mapa necesario para navegar el laberinto de la infraestructura.
Para los equipos que buscan mejorar la estabilidad de su infraestructura, comiencen mapeando su estado actual. Identifiquen los nodos, las conexiones y las dependencias. Una vez que tengan el mapa, el camino hacia la optimización se vuelve claro.

