











Die Softwarearchitektur beruht stark auf visueller Kommunikation. Unter den verschiedenen verfügbaren Werkzeugen bleibt die Unified Modeling Language (UML) die Branchenstandard. Insbesondere dient das UML-Klassendiagramm als Grundlage für die objektorientierte Gestaltung. Allerdings gibt es weit verbreitete Missverständnisse bezüglich seines Zwecks, seiner Anwendung und seines Nutzens. Diese Missverständnisse führen oft zu schlechten Dokumentationspraktiken oder aufgegebenen Modellierungsversuchen. Dieser Leitfaden zerlegt gängige Mythen, um ein klares Verständnis dafür zu vermitteln, wie Klassendiagramme in professionellen Entwicklungs-Umgebungen funktionieren. 🧐
🏗️ Das Fundament verstehen: Was ist ein Klassendiagramm?
Ein UML-Klassendiagramm stellt die statische Struktur eines Systems dar. Es zeigt die Klassen des Systems, deren Attribute, Operationen und die Beziehungen zwischen Objekten. Im Gegensatz zu Sequenzdiagrammen, die sich auf das Verhalten im Zeitverlauf konzentrieren, fokussieren Klassendiagramme auf die Substantive des Systems. Sie beantworten die Frage: Aus welchen Bestandteilen besteht dieses System? 🤔
Viele Entwickler betrachten diese Diagramme lediglich als Skizzen zur Codegenerierung. Obwohl die Forward Engineering-Technik existiert, liegt der primäre Wert in der Kommunikation. Sie dienen als gemeinsame Sprache zwischen Stakeholdern, Architekten und Entwicklern. Ohne ein klares strukturelles Modell geraten Teams oft in inkonsistente Implementierungen. Das Diagramm fungiert als Vertrag für die Codestruktur, bevor überhaupt ein einziger Logik-Codezeile geschrieben wurde.
Wichtige Bestandteile sind:
- Klassen: Die Baupläne für Objekte.
- Attribute: Die Daten, die innerhalb einer Klasse gespeichert werden.
- Operationen: Die verfügbaren Methoden oder Funktionen.
- Beziehungen: Die Verbindungen, die Klassen miteinander verknüpfen.
- Einschränkungen: Regeln, die die Gültigkeit des Modells regeln.
🚫 Mythos 1: Sie sind nur Code-Skelette
Eine verbreitete Überzeugung besagt, dass Klassendiagramme lediglich hochgradige Darstellungen des Codes sind. Einige argumentieren, dass es Codegenerierungstools gibt, weshalb das Diagramm überflüssig sei. Diese Sichtweise ignoriert den semantischen Wert des Modells. Der Code entwickelt sich schnell; ein Diagramm erfasst die Absicht hinter dem Code. Wenn ein Entwickler die Logik ändert, muss das Diagramm möglicherweise nicht geändert werden, solange die Schnittstelle stabil bleibt. Wenn sich jedoch die strukturellen Beziehungen ändern, muss das Diagramm aktualisiert werden, um die neue Realität widerzuspiegeln. 🔧
Darüber hinaus ermöglichen Diagramme Abstraktion. Sie können ein System auf hoher Ebene modellieren, ohne jedes private Attribut zu beschreiben. Diese Abstraktion hilft Stakeholdern, die Geschäftslogik zu verstehen, ohne in Implementierungsdetails verstrickt zu werden. Code ist zu spezifisch; Diagramme sind dafür konzipiert, allgemein gehalten zu werden. Sich ausschließlich auf den Code als Dokumentation zu verlassen, führt zu einem Wartungs-Alptraum, wenn Teammitglieder wechseln. Ein gut gepflegtes Diagramm bietet eine Karte, die auch nach Refaktorisierungen Bestand hat.
🚫 Mythos 2: Sie müssen alles vor dem Codieren zeichnen
Ein weiterer verbreiteter Irrtum ist die Notwendigkeit von Big Design Up Front (BDUF). Kritiker argumentieren, dass das Zeichnen jeder einzelnen Klasse vor dem Schreiben des Codes die agile Entwicklung verlangsamt. Obwohl es wahr ist, dass umfangreiche Vorabmodellierung kontraproduktiv sein kann, ist es ebenso ein Fehler, Diagramme vollständig aufzugeben. Die Wahrheit liegt in der iterativen Gestaltung. 🔄
Effektives Modellieren erfolgt in Schichten:
- Konzeptuelles Modell: Frühe Phase, hochgradige Domänenklassen.
- Entwurfsmodell: Detaillierte Struktur, einschließlich Schnittstellen und Muster.
- Implementierungsmodell: Spezifika für die endgültige Codebasis.
Sie müssen nicht sofort jedes einzelne Getter- und Setter-Element dokumentieren. Konzentrieren Sie sich auf die Beziehungen, die die Komplexität antreiben. Wenn eine Klasse trivial ist, braucht sie möglicherweise keinen Eintrag im Diagramm. Wenn sie komplexe Geschäftsregeln enthält oder mit externen Systemen verbunden ist, erfordert sie eine detaillierte Modellierung. Gleichgewicht ist entscheidend. Das Ziel ist es, Unklarheiten zu reduzieren, nicht bürokratische Hürden zu schaffen.
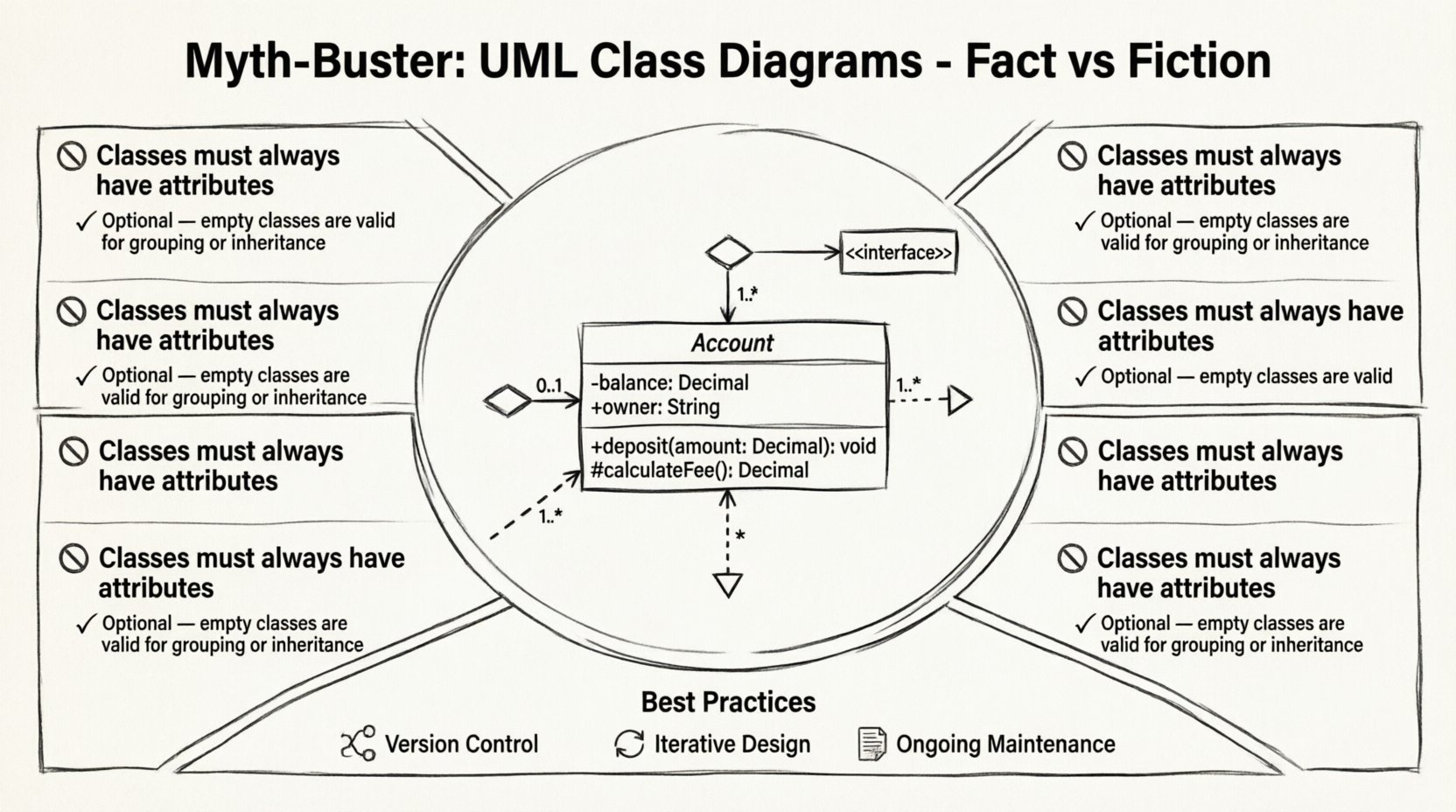
🔗 Mythos 3: Beziehungen sind einfache Linien
Visuelle Einfachheit verbirgt oft semantische Komplexität. Eine Linie, die zwei Felder verbindet, erzählt nicht die ganze Geschichte. In UML 2.5 gibt es zehn verschiedene Beziehungstypen, und ihre falsche Verwendung führt zu architektonischem Verschuldung. Die entscheidendsten Unterschiede bestehen zwischen Assoziation, Aggregation und Komposition. Die Verwechslung dieser Konzepte führt zu engem Kopplung und zerbrechlichen Systemen. ⚠️
Tiefgang: Feinheiten von Beziehungen
Das Verständnis des Unterschieds zwischen diesen drei ist für eine robuste Gestaltung unerlässlich. Sie stellen unterschiedliche Lebenszyklusabhängigkeiten und Eigentumsstrukturen dar.
| Beziehungstyp | Symbol | Bedeutung | Beispiel |
|---|---|---|---|
| Assoziation | Linie | Ein genereller Link zwischen Objekten | Ein Lehrer unterrichtet einen Schüler |
| Aggregation | Hohles Diamant-Symbol | Ganzes-Teil-Beziehung (geteilt) | Eine Abteilung hat Mitarbeiter |
| Komposition | Füllendes Diamant-Symbol | Ganzes-Teil-Beziehung (ausschließend) | Ein Haus hat Räume |
| Generalisierung | Dreiecks-Pfeil | Vererbung (Ist-ein) | Auto erweitert Fahrzeug |
| Abhängigkeit | Punktiertes Pfeil-Symbol | Nutzungsbeziehung | Bericht verwendet Datenbank |
Berücksichtigen Sie den Unterschied zwischen Aggregation und Komposition. Bei Aggregation kann der Teil unabhängig vom Ganzen existieren. Wenn die Abteilung aufgelöst wird, existieren die Mitarbeiter weiterhin. Bei Komposition ist der Teil dem Ganzen zugeordnet. Wenn das Haus abgerissen wird, gibt es die Räume nicht mehr. Diese Unterscheidung bestimmt, wie Speicher verwaltet und wie Lebenszyklusereignisse im Code behandelt werden. Die falsche Verwendung eines Beziehungstyps in einer Darstellung führt oft zu falscher Implementierungslogik.
📏 Mythos 4: Vielzahl ist optional
Die Vielzahl definiert, wie viele Instanzen einer Klasse an einer Beziehung teilnehmen. Viele Modelle lassen dies weg, wodurch der Entwickler raten muss. Ist es ein-zu-eins? Ein-zu-viele? Null-zu-viele? Diese Unklarheit führt zu Laufzeitfehlern. Eine Methode, die eine Liste von Objekten erwartet, könnte null erhalten, wenn das Modell null impliziert. 📉
Die Standardnotation für Vielfachheit umfasst:
- 0..1:Optional, kann null oder eins betragen.
- 1..1:Erforderlich, genau eine.
- 1..*:Erforderlich, eine oder mehrere.
- 0..*:Optional, null oder mehr.
Die Ignorierung der Vielfachheit zwingt den Entwickler dazu, verteidigende Code zu schreiben, der eigentlich bereits im Design berücksichtigt werden sollte. Zum Beispiel sollte der Code sicherstellen, dass ein Benutzer genau ein Profil haben muss, und diese Einschränkung auf der Datenbankebene implementiert werden. Das Diagramm vermittelt diese Anforderung an den Datenbankarchitekten. Es stellt sicher, dass die Logik mit dem ursprünglichen Intent übereinstimmt. Das Weglassen dieser Details ist eine Form von Nachlässigkeit in der Entwurfsphase.
🧩 Mythos 5: UML ist nur für große Systeme geeignet
Es besteht die Ansicht, dass UML-Diagramme nur für enterprise-scale-Anwendungen reserviert sind. Kleine Skripte und Microservices benötigen sie nicht. Das ist falsch. Selbst kleine Systeme weisen strukturelle Abhängigkeiten auf. Wenn Codebasen wachsen, wird das Refactoring ohne eine Karte schwieriger. Eine Microservice-Architektur erfordert weiterhin definierte Schnittstellen und Datenmodelle. 📦
In kleineren Kontexten fungiert das Diagramm als Sinnhaftigkeitsprüfung. Es verhindert das „Spaghetti-Code“-Muster, bei dem Klassen sich wechselseitig in zirkulären Abhängigkeiten befinden. Durch die Visualisierung des Daten- und Objektflusses können Entwickler Kopplungsprobleme früh erkennen. Die Kosten für die Erstellung eines Diagramms bei einem kleinen Projekt sind gering, aber der Nutzen der Klarheit ist hoch. Es dient als lebendiges Dokument, das sich mit dem Projekt entwickelt.
🛠️ Mythos 6: Werkzeuge ersetzen Denken
Automatisierte Reverse-Engineering-Werkzeuge können Diagramme aus Code generieren. Einige glauben, dass dadurch manuelles Modellieren obsolet wird. Während das Reverse Engineering nützlich ist, um veralteten Code zu verstehen, erzeugt es selten saubere, lesbare Modelle. Der Code enthält Implementierungsdetails, die Diagramme verunreinigen. Ein generiertes Diagramm zeigt oft jede private Variable und Methode, wodurch es unleserlich wird. 🤖
Manuelles Modellieren erfordert Gestaltungsentscheidungen. Es zwingt den Architekten dazu, das Wichtige zu priorisieren. Es trennt die logische Sicht von der physischen Sicht. Automatisierte Werkzeuge sind am besten für die Synchronisation, nicht für die Erstellung geeignet. Die reine Abhängigkeit von Werkzeugen entfernt den kritischen Denkprozess aus der Entwurfsphase. Der Wert liegt im Modellierungsprozess selbst, nicht in der Ausgabedatei.
🎨 Mythos 7: Sichtbarkeitsmodifizierer sind trivial
Zugriffsmodifizierer (public, private, protected) werden oft als Implementierungsdetails behandelt. In einem Klassendiagramm definieren sie den Vertrag. Die Änderung einer öffentlichen Methode in private ist eine Breaking Change für jede externe Klasse. Ein Diagramm macht diese Abhängigkeiten sichtbar. 🚧
Beim Modellieren sollten folgende Aspekte berücksichtigt werden:
- Öffentlich:Erreichbar von jeder anderen Klasse. Die Schnittstelle.
- Privat:Interne Implementierungsdetails. Vor anderen verborgen.
- Geschützt:Erreichbar von der Klasse und ihren Unterklassen.
Das Überexponieren öffentlicher Methoden erhöht die Kopplung. Ein gut gestaltetes Diagramm minimiert die öffentliche Sichtbarkeit, um die Angriffsfläche für Fehler zu reduzieren. Es fördert die Kapselung. Wenn eine Klasse zu viele öffentliche Attribute offenlegt, wird sie zu einer „Datenstruktur“ statt zu einem Objekt mit Verhalten. Das Diagramm hilft dabei, solche Verstöße frühzeitig zu erkennen.
🔄 Mythos 8: Diagramme benötigen keine Wartung
Vielleicht der gefährlichste Mythos ist, dass Diagramme statische Artefakte sind. Sobald sie gezeichnet wurden, werden sie vergessen. Wenn sich der Code ändert, bleibt das Diagramm oft veraltet. Dadurch entsteht eine „falsche Wahrheit“, bei der die Dokumentation nicht mehr mit dem System übereinstimmt. 📉
Um Diagramme nutzbar zu halten:
- Versionskontrolle: Behandle Diagramme wie Code. Commite Änderungen.
- Synchronisationspunkte:Aktualisiere Diagramme während der Code-Reviews.
- Refactoring: Wenn sich die Klassenstruktur ändert, aktualisiere das Diagramm sofort.
- Überprüfung: Überprüfe Diagramme regelmäßig anhand des tatsächlichen Codebases.
Wenn ein Diagramm veraltet wird, wird es zu einer Belastung. Entwickler könnten dem Diagramm folgen und Fehler einführen. Es ist besser, ein einfaches, aktuelles Diagramm zu haben, als ein komplexes, veraltetes. Manchmal ist es besser, ein Diagramm zu entfernen, als eine Lüge aufrechtzuerhalten. Genauigkeit ist die primäre Währung der Dokumentation.
🧠 Abstrakte Klassen und Schnittstellen
Den Unterschied zwischen abstrakten Klassen und Schnittstellen zu erkennen, ist ein häufiger Stolperstein. Beide repräsentieren Abstraktionen, dienen aber unterschiedlichen Zwecken. Eine abstrakte Klasse stellt eine teilweise Implementierung dar. Sie kann Zustand und konkrete Methoden enthalten. Eine Schnittstelle stellt einen Vertrag dar. Sie definiert Verhalten ohne Implementierung. 🤝
In einem Klassendiagramm wird dies durch spezifische Notationen dargestellt. Abstrakte Klassen haben oft kursiv geschriebene Namen. Schnittstellen werden mit dem Stereotyp <<interface>> gekennzeichnet. Die Verwechslung dieser Elemente führt zu Vererbungsproblemen. Eine Klasse kann nur eine abstrakte Klasse erweitern, aber mehrere Schnittstellen implementieren. Diese Unterscheidung bestimmt die Gestaltungsfreiheit des Systems. Das Verständnis dieser Unterschiede hilft dabei, die richtige Abstraktion für das jeweilige Problem zu wählen.
📉 Gestaltung für Veränderungen
Software ist niemals statisch. Anforderungen ändern sich. Technologien entwickeln sich weiter. Ein gutes Klassendiagramm antizipiert Veränderungen. Es trennt stabile Teile von instabilen Teilen. Zum Beispiel sollte das Kern-Domänenmodell stabil bleiben, während die Infrastruktur-Schicht häufig wechselt. Die Gruppierung von Klassen nach Schichten im Diagramm hilft, diese Trennung visuell darzustellen. 🏛️
Die Abhängigkeitsinversion ist ein Prinzip, das von guter Modellierung profitiert. Hochrangige Module sollten nicht von niedrigrangigen Modulen abhängen. Beide sollten von Abstraktionen abhängen. Das Diagramm macht diese Abhängigkeiten deutlich. Wenn du ein dichtes Netz aus Pfeilen siehst, die konkrete Klassen verbinden, ist das Design brüchig. Ziel ist es, die Anzahl der Abhängigkeiten zwischen Klassen zu minimieren. Dadurch wird die Auswirkung von Änderungen reduziert.
✅ Abschließende Gedanken
Das UML-Klassendiagramm ist ein mächtiges Werkzeug, wenn es richtig eingesetzt wird. Es trennt das Konzept der Struktur von der Realität des Codes. Indem man die Mythen um seine Verwendung entlarvt, können Teams einen disziplinierteren Ansatz für die Architektur verfolgen. Es geht nicht darum, hübsche Bilder zu zeichnen. Es geht um Klarheit, Kommunikation und Risikominderung. 🛡️
Denke daran, dass das Diagramm der Team dient, nicht dem Werkzeug. Es sollte regelmäßig aktualisiert werden. Beziehungen müssen präzise sein. Die Vielzahl sollte explizit sein. Sichtbarkeit sollte bewusst gewählt werden. Wenn diese Prinzipien angewendet werden, wird das Klassendiagramm zu einer zuverlässigen Karte für die Reise der Softwareentwicklung. Es führt das Team durch die Komplexität, ohne sich in den Details zu verlieren. Halte dich an die Fakten, vermeide die Hype und gestalte mit Absicht. 🚀

