











L’architecture logicielle repose fortement sur la communication visuelle. Parmi les divers outils disponibles, le langage de modélisation unifié (UML) reste la norme de l’industrie. Plus précisément, le diagramme de classes UML constitue le pilier de la conception orientée objet. Toutefois, des idées fausses répandues entourent son objectif, son application et son utilité. Ces malentendus entraînent souvent de mauvaises pratiques de documentation ou des projets de modélisation abandonnés. Ce guide démonte les mythes courants afin de fournir une compréhension claire du fonctionnement des diagrammes de classes dans les environnements de développement professionnels. 🧐
🏗️ Comprendre les fondations : qu’est-ce qu’un diagramme de classes ?
Un diagramme de classes UML représente la structure statique d’un système. Il affiche les classes du système, leurs attributs, leurs opérations et les relations entre les objets. Contrairement aux diagrammes de séquence, qui se concentrent sur le comportement dans le temps, les diagrammes de classes se concentrent sur les noms propres du système. Ils répondent à la question : De quoi se compose ce système ? 🤔
Beaucoup de développeurs considèrent ces diagrammes comme de simples croquis destinés à la génération de code. Bien que l’ingénierie ascendante existe, la valeur principale réside dans la communication. Ils servent de langage commun entre les parties prenantes, les architectes et les développeurs. Sans un modèle structurel clair, les équipes dérivent souvent vers des implémentations incohérentes. Le diagramme agit comme un contrat pour la structure du code avant qu’une seule ligne de logique ne soit écrite.
Les composants clés incluent :
- Classes : Les plans directeurs des objets.
- Attributs : Les données stockées au sein d’une classe.
- Opérations : Les méthodes ou fonctions disponibles.
- Relations : Les liens reliant les classes entre elles.
- Contraintes : Des règles régissant la validité du modèle.
🚫 Mythe 1 : Ce sont simplement des squelettes de code
Une croyance répandue suggère que les diagrammes de classes ne sont que des représentations de haut niveau du code. Certains affirment que, puisque des outils de génération de code existent, le diagramme est redondant. Cette vision ignore la valeur sémantique du modèle. Le code évolue rapidement ; un diagramme capture l’intention derrière le code. Si un développeur modifie la logique, le diagramme n’a peut-être pas besoin de changer si l’interface reste stable. Toutefois, si les relations structurelles évoluent, le diagramme doit être mis à jour pour refléter la nouvelle réalité. 🔧
En outre, les diagrammes permettent l’abstraction. Vous pouvez modéliser un système à un niveau élevé sans détailler chaque variable privée. Cette abstraction aide les parties prenantes à comprendre la logique métier sans s’embrouiller dans les détails d’implémentation. Le code est trop spécifique ; les diagrammes sont conçus pour être généralisés. Se fier uniquement au code comme documentation crée un cauchemar de maintenance lorsque les membres de l’équipe changent. Un diagramme bien maintenu fournit une carte qui résiste au restructurage.
🚫 Mythe 2 : Vous devez dessiner tout avant de coder
Une autre idée fausse courante est la nécessité d’un grand design initial (BDUF). Les critiques affirment que dessiner chaque classe individuellement avant d’écrire du code ralentit le développement agile. Bien qu’il soit vrai que la modélisation exhaustive au départ peut être contre-productive, abandonner complètement les diagrammes est également une erreur. La vérité réside dans la conception itérative. 🔄
La modélisation efficace se fait par couches :
- Modèle conceptuel : Phase initiale, classes de domaine de haut niveau.
- Modèle de conception : Structure détaillée, incluant les interfaces et les motifs.
- Modèle d’implémentation : Détails pour la base de code finale.
Vous n’avez pas besoin de documenter immédiatement chaque getter et setter. Concentrez-vous sur les relations qui génèrent de la complexité. Si une classe est triviale, elle n’a peut-être pas besoin d’une entrée dans le diagramme. Si elle contient des règles métier complexes ou interagit avec des systèmes externes, elle nécessite une modélisation détaillée. L’équilibre est essentiel. L’objectif est de réduire l’ambiguïté, et non de créer une surcharge bureaucratique.
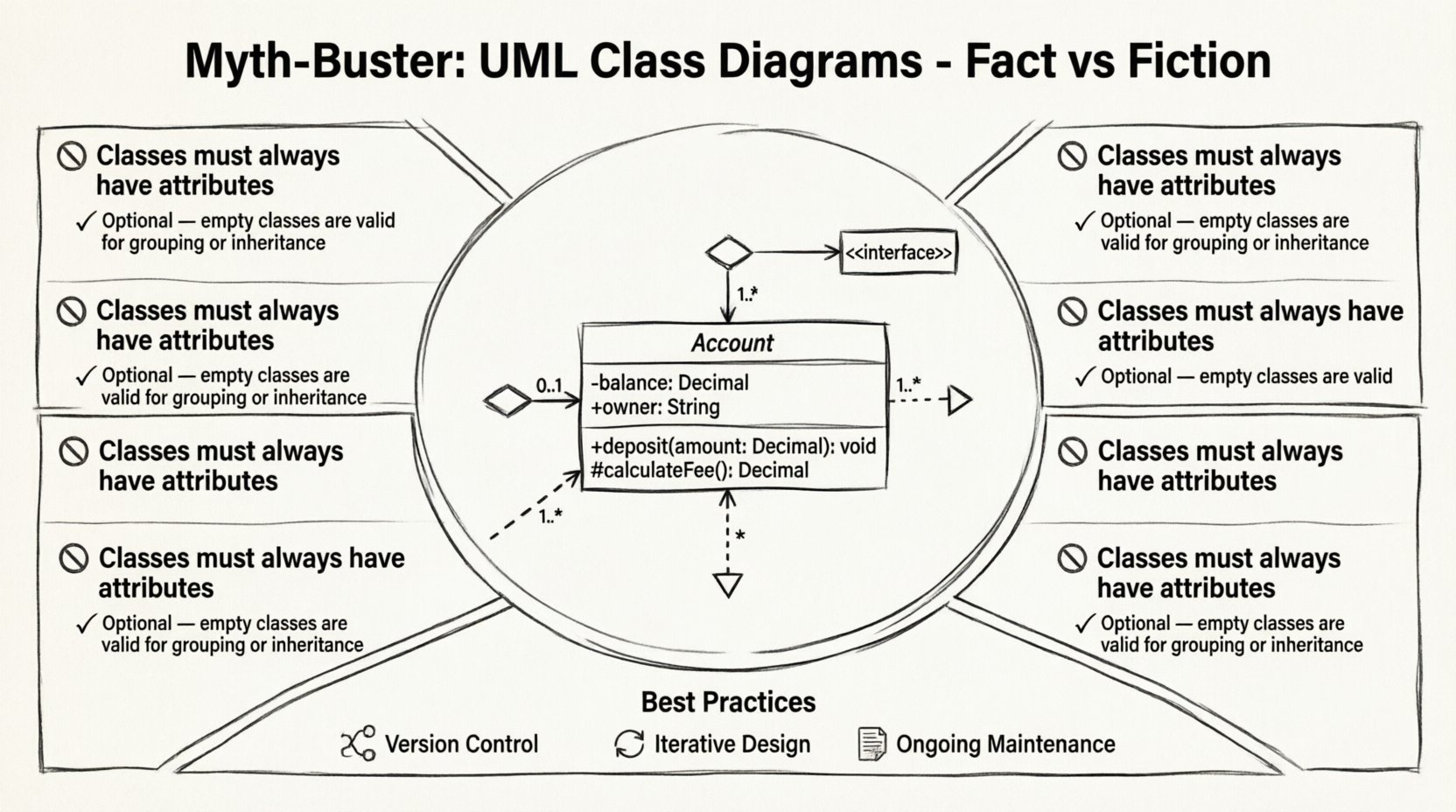
🔗 Mythe 3 : Les relations sont de simples lignes
La simplicité visuelle masque souvent la complexité sémantique. Une ligne reliant deux boîtes ne raconte pas toute l’histoire. Il existe dix types de relations distincts dans UML 2.5, et leur mauvais usage entraîne une dette architecturale. Les distinctions les plus importantes existent entre Association, Agrégation et Composition. Confondre ces concepts entraîne un couplage étroit et des systèmes fragiles. ⚠️
Approfondissement : Les subtilités des relations
Comprendre la différence entre ces trois éléments est essentiel pour une conception robuste. Ils représentent des dépendances de cycle de vie et des structures de propriété différentes.
| Type de relation | Symbole | Signification | Exemple |
|---|---|---|---|
| Association | Ligne | Un lien générique entre objets | Un enseignant enseigne à un élève |
| Agrégation | Diamant creux | Relation tout-partie (partagée) | Un département possède des employés |
| Composition | Diamant plein | Relation tout-partie (exclusive) | Une maison possède des chambres |
| Généralisation | Flèche triangulaire | Héritage (Est-Un) | Voiture étend Véhicule |
| Dépendance | Flèche pointillée | Relation d’utilisation | Le rapport utilise la base de données |
Considérez la différence entre Agrégation et Composition. Dans l’Agrégation, la partie peut exister indépendamment du tout. Si le département est dissous, les employés existent toujours. Dans la Composition, la partie est détenue par le tout. Si la maison est démolie, les chambres cessent d’exister. Cette distinction détermine la gestion de la mémoire et le traitement des événements de cycle de vie dans le code. Utiliser le mauvais type de relation dans un diagramme conduit souvent à une logique d’implémentation incorrecte.
📏 Mythe 4 : La multiplicité est facultative
La multiplicité définit combien d’instances d’une classe participent à une relation. De nombreux modèles omettent cela, laissant le développeur deviner. S’agit-il d’un à un ? D’un à plusieurs ? De zéro à plusieurs ? Laisser cela ambigu entraîne des erreurs à l’exécution. Une méthode qui attend une liste d’objets pourrait recevoir null si le modèle implique zéro. 📉
La notation de multiplicité standard inclut :
- 0..1:Facultatif, peut être zéro ou un.
- 1..1:Requis, exactement un.
- 1..*:Requis, un ou plusieurs.
- 0..*:Facultatif, zéro ou plusieurs.
Ignorer la multiplicité oblige le développeur à écrire du code défensif qui aurait dû être prévu dès le départ. Par exemple, si un Utilisateur doit avoir exactement un Profil, le code doit imposer cette contrainte au niveau de la base de données. Le diagramme communique cette exigence à l’architecte de la base de données. Il garantit que la logique correspond à l’intention. Omettre ces détails constitue une forme de négligence à l’étape de conception.
🧩 Mythe 5 : UML est uniquement réservé aux grands systèmes
On croit que les diagrammes UML sont réservés aux applications à l’échelle d’entreprise. Les petits scripts et les microservices n’en ont pas besoin. Cela est incorrect. Même les petits systèmes ont des dépendances structurelles. À mesure que les bases de code grandissent, le restructurage devient plus difficile sans carte. Une architecture de microservices nécessite toujours des interfaces et des modèles de données définis. 📦
Dans des contextes plus petits, le diagramme agit comme un contrôle de bon sens. Il empêche le schéma de « code spaghetti » où les classes dépendent les unes des autres de manière circulaire. En visualisant le flux des données et des objets, les développeurs peuvent détecter tôt les problèmes d’interdépendance. Le coût de la réalisation d’un diagramme pour un petit projet est faible, mais le bénéfice de clarté est élevé. Il sert de document vivant qui évolue avec le projet.
🛠️ Mythe 6 : Les outils remplacent la réflexion
Les outils automatisés de reverse-engineering peuvent générer des diagrammes à partir du code. Certains pensent que cela rend le modélisation manuelle obsolète. Bien que le reverse-engineering soit utile pour comprendre le code hérité, il produit rarement des modèles propres et lisibles. Le code contient des détails d’implémentation qui encombrent les diagrammes. Un diagramme généré montre souvent chaque variable et méthode privée, le rendant illisible. 🤖
La modélisation manuelle exige des décisions de conception. Elle oblige l’architecte à prioriser ce qui est important. Elle sépare la vue logique de la vue physique. Les outils automatisés sont mieux utilisés pour la synchronisation, et non pour la création. Se fier uniquement aux outils élimine le processus de réflexion critique de la phase de conception. La valeur réside dans l’acte de modélisation, et non dans le fichier de sortie.
🎨 Mythe 7 : Les modificateurs de visibilité sont triviaux
Les modificateurs d’accès (public, privé, protégé) sont souvent traités comme des détails d’implémentation. Dans un diagramme de classe, ils définissent le contrat. Changer une méthode publique en privée constitue un changement cassant pour toute classe externe. Un diagramme rend ces dépendances visibles. 🚧
Lors de la modélisation, considérez :
- Public :Accessible par n’importe quelle autre classe. L’interface.
- Privé :Détails d’implémentation internes. Cachés aux autres.
- Protégé :Accessible par la classe et ses sous-classes.
Exposer trop de méthodes publiques augmente le couplage. Un diagramme bien conçu minimise la visibilité publique pour réduire la surface d’erreurs. Il encourage l’encapsulation. Si une classe expose trop d’attributs publics, elle devient une « structure de données » plutôt qu’un objet ayant un comportement. Le diagramme aide à identifier quand cette violation se produit.
🔄 Mythe 8 : Les diagrammes n’ont pas besoin d’être entretenus
Peut-être le mythe le plus dangereux est que les diagrammes sont des artefacts statiques. Une fois dessinés, ils sont oubliés. Lorsque le code change, le diagramme est souvent laissé obsolète. Cela crée une « vérité fausse » où la documentation ne correspond plus au système. 📉
Pour garder les diagrammes utiles :
- Contrôle de version : Traitez les diagrammes comme du code. Validez les modifications.
- Points de synchronisation : Mettez à jour les diagrammes lors des revues de code.
- Refactoring : Si la structure de la classe change, mettez à jour le diagramme immédiatement.
- Revue : Auditez périodiquement les diagrammes par rapport au code réel.
Si un diagramme devient obsolète, il devient une charge. Les développeurs peuvent suivre le diagramme et introduire des bogues. Il vaut mieux avoir un diagramme simple et à jour qu’un diagramme complexe et obsolète. Parfois, supprimer un diagramme est préférable à le conserver comme mensonge. La précision est la monnaie principale de la documentation.
🧠 Classes abstraites et interfaces
Différencier les classes abstraites et les interfaces est une difficulté courante. Les deux représentent des abstractions, mais elles ont des rôles différents. Une classe abstraite représente une implémentation partielle. Elle peut contenir un état et des méthodes concrètes. Une interface représente un contrat. Elle définit un comportement sans implémentation. 🤝
Dans un diagramme de classes, cela est indiqué par des notations spécifiques. Les classes abstraites ont souvent leurs noms en italique. Les interfaces sont marquées par le stéréotype <<interface>>. Les confondre entraîne des problèmes d’héritage. Une classe ne peut hériter que d’une seule classe abstraite, mais peut implémenter plusieurs interfaces. Cette distinction détermine la flexibilité du design du système. Comprendre cela aide à choisir l’abstraction appropriée pour le problème à résoudre.
📉 Concevoir pour le changement
Le logiciel n’est jamais statique. Les exigences évoluent. Les technologies évoluent. Un bon diagramme de classes anticipe les changements. Il sépare les parties stables des parties volatiles. Par exemple, le modèle central du domaine doit rester stable, tandis que la couche d’infrastructure change fréquemment. Regrouper les classes par couche dans le diagramme aide à visualiser cette séparation. 🏛️
L’inversion de dépendance est un principe qui bénéficie d’un bon modèle. Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre d’abstractions. Le diagramme rend ces dépendances explicites. Si vous voyez un réseau épais de flèches reliant des classes concrètes, le design est fragile. L’objectif est de minimiser le nombre de dépendances entre les classes. Cela réduit l’impact des modifications.
✅ Réflexions finales
Le diagramme de classes UML est un outil puissant lorsqu’il est utilisé correctement. Il sépare le concept de structure de la réalité du code. En démentant les mythes entourant son utilisation, les équipes peuvent adopter une approche plus disciplinée de l’architecture. Ce n’est pas seulement dessiner de jolies images. C’est clarté, communication et réduction des risques. 🛡️
Souvenez-vous que le diagramme sert l’équipe, et non l’outil. Il doit être mis à jour régulièrement. Les relations doivent être précises. La multiplicité doit être explicite. La visibilité doit être intentionnelle. Lorsque ces principes sont appliqués, le diagramme de classes devient une carte fiable pour le parcours du développement logiciel. Il guide l’équipe à travers la complexité sans se perdre dans les détails. Restez sur les faits, évitez la hype, et concevez avec intention. 🚀

