











In der Landschaft der Softwareentwicklung ist Klarheit Währung. Architekten und Entwickler verlassen sich auf visuelle Modelle, um komplexe Systeme zu verstehen. Unter den Spezifikationen der Unified Modeling Language (UML) hebt sich das Klassendiagramm als Grundlage der objektorientierten Gestaltung hervor. Traditionell erforderte die Erstellung dieser Diagramme manuelle Arbeit, was oft dazu führte, dass die Dokumentation hinter dem Code zurückblieb. Die Einführung automatisierter Generierungstools hat dieses Paradigma verändert. Dieser Leitfaden untersucht die technischen Realitäten, Vorteile und Grenzen der automatischen Erzeugung von UML-Klassendiagrammen.
Das Verständnis der Kompromisse ist entscheidend, um die architektonische Integrität zu wahren. Während die Automatisierung die Dokumentation beschleunigt, ersetzt sie nicht das Gestaltungsdenken. Dieser Artikel untersucht die Mechanismen der Code-zu-Diagramm-Konvertierung, die Treue des Outputs und wie Teams diese Werkzeuge in bestehende Arbeitsabläufe integrieren können, ohne die Qualität zu beeinträchtigen.
Definition der automatisierten UML-Generierung 🛠️
Die automatisierte UML-Generierung bezeichnet den Prozess, bei dem Softwarewerkzeuge strukturelle Informationen direkt aus dem Quellcode extrahieren, um eine visuelle Darstellung zu erstellen. Anstatt Kästchen und Linien manuell zu zeichnen, analysiert das Werkzeug die Codebasis, identifiziert Klassen, Schnittstellen und Vererbungshierarchien und ordnet sie UML-Symbolen zu.
Dieser Prozess beruht auf statischer Analyse. Das Werkzeug liest den abstrakten Syntaxbaum (AST) der Programmiersprache. Es führt den Code nicht aus, sondern untersucht die Definitionen. Diese Unterscheidung ist entscheidend. Das Diagramm spiegelt die statische Struktur wider, nicht das Laufzeitverhalten. Zum Beispiel zeigt es, dass Klasse A von Klasse B erbt, aber nicht den dynamischen Zustand einer Instanz von A während einer bestimmten Operation.
Das primäre Ziel ist es, die Kluft zwischen Implementierung und Dokumentation zu überbrücken. In vielen Projekten wird die Dokumentation kurz nach der Freigabe veraltet. Die automatisierte Generierung zielt darauf ab, das Modell mit dem Quellcode synchron zu halten und die Wartungsarbeiten zu reduzieren, die mit der Aktualisierung von Diagrammen verbunden sind.
Mechanismen: Vorwärts- vs. Rückwärtsingenieurwesen 🔄
Die automatisierte Generierung fällt im Allgemeinen in zwei Kategorien, abhängig von der Richtung des Arbeitsablaufs. Das Verständnis des Unterschieds hilft Teams, zu entscheiden, welcher Ansatz ihrem Projektzyklus am besten entspricht.
1. Vorwärtsingenieurwesen (Code zu Diagramm)
Das Vorwärtsingenieurwesen beinhaltet das Nehmen vorhandenen Codes und die Erzeugung eines Diagramms. Dies ist die häufigste Form der Automatisierung. Sie wird typischerweise verwendet für:
- Onboarding:Neue Entwickler müssen die Codebasis schnell verstehen.
- Refactoring:Architekten visualisieren die Auswirkungen struktureller Änderungen, bevor sie angewendet werden.
- Veraltete Systeme:Projekte ohne Dokumentation erfordern eine sofortige Visualisierung, um die Wartung beginnen zu können.
Das Werkzeug scannet das Repository, identifiziert Klassendefinitionen und erstellt das Diagramm. Es ordnet Methoden und Attribute basierend auf Sichtbarkeitsmodifizierern (public, private, protected) zu. Es setzt jedoch voraus, dass der Code gut strukturiert ist. Wenn Variablennamen unklar sind, spiegelt das Diagramm diese Unklarheit wider.
2. Rückwärtsingenieurwesen (Diagramm zu Code)
Das Rückwärtsingenieurwesen nimmt ein visuelles Modell und generiert Code-Skelette. Obwohl es in modernen agilen Umgebungen weniger verbreitet ist, dient es bestimmten Zwecken:
- Prototyping:Entwerfen der Struktur, bevor Implementierungslogik geschrieben wird.
- Standardisierung:Sicherstellen, dass neuer Code etablierten architektonischen Mustern folgt.
- Migration:Konvertieren von Entwürfen von einer Sprache in eine andere.
Dieser Ansatz erfordert, dass das Werkzeug die Absicht des Diagramms interpretiert. Unklarheiten im visuellen Modell können zu generischen Code-Skeletten führen, die erhebliche manuelle Nacharbeit erfordern. Es ist ein Ausgangspunkt, kein fertiges Produkt.
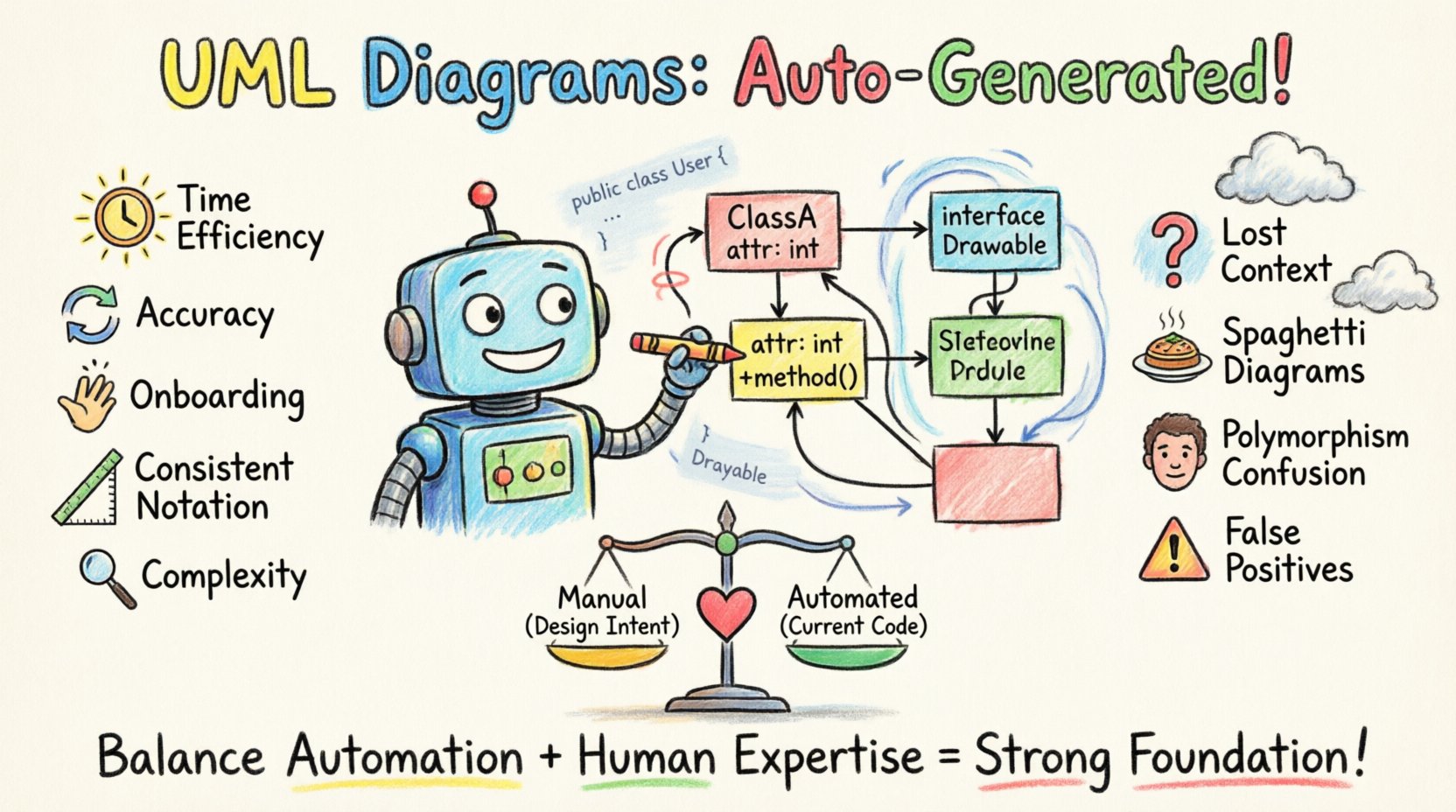
Die Vorteile der Automatisierung 📈
Warum investieren Teams in diese Werkzeuge? Die Vorteile sind greifbar und treiben oft Effizienzgewinne voran. Der primäre Nutzen liegt in der Synchronisation und Sichtbarkeit.
- Zeiteffizienz: Die manuelle Erstellung eines Diagramms für eine große Unternehmensanwendung kann Wochen dauern. Automatisierte Werkzeuge erstellen den ersten Entwurf in Minuten. Dadurch können Architekten sich auf die hochwertige Gestaltung konzentrieren, anstatt Rechtecke zu zeichnen.
- Genauigkeit und Synchronisation: Manuelle Diagramme verlieren ihre Aktualität. Wenn ein Entwickler eine Methode hinzufügt, wird das Diagramm erst aktualisiert, wenn jemand daran denkt, es zu ändern. Automatisierte Werkzeuge spiegeln den aktuellen Zustand des Repositories wider. Dadurch sinkt das Risiko, Entscheidungen auf Basis veralteter Informationen zu treffen.
- Beschleunigung der Einarbeitung:Die Visualisierung des Abhängigkeitsgraphen hilft Neulingen, die Systemtopologie zu verstehen. Er zeigt komplexe Kopplungen auf, die in tiefen Verzeichnisstrukturen versteckt sein könnten.
- Konsistenz in der Notation:Werkzeuge setzen standardisierte UML-Regeln durch. Es gibt keine Abweichungen bei der Darstellung von Vererbung oder der Beschriftung von Assoziationen. Dadurch entsteht eine einheitliche Sprache für das Team.
- Erkennung von Komplexität:Werkzeuge berechnen häufig Metriken neben dem Diagramm, wie z. B. zyklomatische Komplexität oder Kopplungstiefe. Diese Metriken heben Klassen hervor, die zu groß oder zu stark von anderen abhängig sind.
Die Herausforderungen und Einschränkungen 📉
Trotz der Vorteile ist Automatisierung keine Allheilmittel. Es gibt erhebliche technische und praktische Einschränkungen, die Teams erkennen müssen, um Frustration zu vermeiden.
- Verlust des semantischen Kontexts:Der Code enthält Logik, Diagramme zeigen jedoch nur die Struktur. Ein Diagramm kann nicht erklären, warumeine Klasse existiert oder die spezifischen Geschäftsregeln, die sie durchsetzt. Die Feinheiten der Implementierung gehen bei der Abstraktion verloren.
- Schnittstelle vs. Implementierung:Automatisierte Werkzeuge haben oft Schwierigkeiten, zwischen dem Vertrag (Schnittstelle) und der Realisierung (Implementierung) zu unterscheiden. Sie zeigen möglicherweise alle Methoden an und verunreinigen die Ansicht mit Boilerplate-Code, der zur architektonischen Verständlichkeit beiträgt.
- Umgang mit Polymorphie:Dynamische Typisierung und Laufzeit-Polymorphie sind schwer statisch darzustellen. Ein Diagramm könnte eine Basisklasse zeigen, aber die spezifische abgeleitete Klasse, die in der Produktion verwendet wird, hängt von Konfigurationen oder Laufzeitbedingungen ab. Die statische Ansicht kann irreführend sein.
- Abhängigkeitsauflösung:In großen monolithischen Systemen kann das Diagramm zu einem „Spaghetti“-Durcheinander werden. Wenn das Werkzeug keine Filter für Ansichten bietet, könnte ein einziger Bildschirm Tausende von Klassen und Linien zeigen. Damit wird das Ziel der Vereinfachung zunichte gemacht.
- Falsch positive Ergebnisse in der Gestaltung:Werkzeuge können keine Designmuster validieren. Sie zeichnen eine Klasse als „Singleton“, wenn der Code darauf hindeutet, aber sie können nicht überprüfen, ob das Muster korrekt implementiert wurde oder ob es sich um ein Anti-Muster handelt.
- Versionskontroll-Abweichung: Wenn das Werkzeug nicht in die Build-Pipeline integriert ist, könnte das generierte Diagramm veraltet sein. Die Abhängigkeit von einer statischen Datei, die vor Monaten erstellt wurde, birgt ein Risiko.
Vergleichsanalyse: Manuell vs. Automatisiert ⚖️
Um die Vor- und Nachteile klarzustellen, betrachten Sie den folgenden Vergleich der Eigenschaften zwischen der traditionellen manuellen Erstellung und der automatisierten Generierung.
| Funktion | Manuelle Erstellung | Automatisierte Generierung |
|---|---|---|
| Geschwindigkeit | Langsam (Stunden/Tage) | Schnell (Minuten) |
| Genauigkeit | Hoch (Absichtsmäßig) | Hoch (aktueller Code) |
| Wartung | Hoher Aufwand | Geringer Aufwand |
| Zusammenhang | Hoch (Designabsicht) | Niedrig (nur Struktur) |
| Konsistenz | Variabel (Menschliches Fehlverhalten) | Hoch (Werkzeugstandard) |
| Kosten | Hoch (Arbeitskraft) | Mittel (Werkzeug) |
Die Tabelle zeigt, dass die Wahl nicht binär ist. Es geht darum, Absicht mit Realität abzustimmen. Manuelle Diagramme erfassen die Design. Automatisierte Diagramme erfassen die Code.
Strategische Implementierung in Workflows 🚀
Die Integration automatisierter Generierung erfordert eine Prozessverschiebung. Es handelt sich nicht nur um eine Werkzeuginstallation, sondern um eine Änderung des Workflows. Um erfolgreich zu sein, sollten Teams die folgenden Strategien berücksichtigen.
- Integration mit CI/CD: Der Prozess der Diagrammerzeugung sollte Teil der kontinuierlichen Integrationspipeline sein. Jedes Mal, wenn Code zusammengeführt wird, sollte das Diagramm neu generiert werden. Dadurch wird sichergestellt, dass das Artefakt im Repository stets aktuell ist.
- Ansichtsfilterung: Legen Sie nicht das gesamte System in eine Ansicht. Erstellen Sie gefilterte Ansichten basierend auf Untereinheiten, Modulen oder Schichten. Dadurch bleiben die Diagramme lesbar und fokussiert auf den relevanten Bereich.
- Dokumentationspflege: Legen Sie eine Regel fest, dass Diagramme generierte Artefakte sind. Bearbeiten Sie die exportierten Diagrammdateien nicht manuell. Wenn eine Änderung im Modell erforderlich ist, aktualisieren Sie den Code oder die Konfiguration und generieren Sie anschließend neu. Dadurch wird verhindert, dass „Schattendokumentation“ entsteht, die von der Realität abweicht.
- Selektive Automatisierung: Nicht jede Klasse muss in jedem Diagramm enthalten sein. Verwenden Sie Anmerkungen oder Konfigurationsdateien, um Testcode, generierten Code oder Hilfsbibliotheken auszuschließen, die Störgeräusche verursachen.
- Schulung: Stellen Sie sicher, dass das Team versteht, wie man die generierten Diagramme liest. Automatisierte Ausgaben können dicht sein. Entwickler müssen wissen, wie sie die Hierarchie navigieren und die Beziehungen interpretieren können.
Wartungs- und Evolutionsüberlegungen 🧩
Selbst bei Automatisierung ist Wartung erforderlich. Das Diagramm ist eine Abbildung des Codes, und der Code entwickelt sich weiter. Teams müssen den Lebenszyklus des visuellen Modells verwalten.
Code-Rot: Im Laufe der Zeit sammelt sich technische Schuld an. Automatisierte Werkzeuge dokumentieren diese Schuld treu. Wenn eine Klasse übermäßig komplex wird, zeigt das Diagramm dies an. Dies kann als Signal zur Refaktorisierung dienen. Das Diagramm wird zu einem Diagnosewerkzeug.
Versionsverwaltung: Wenn mehrere Versionen eines Systems verwaltet werden, sollten Diagramme zusammen mit dem Code versioniert werden. Dies ermöglicht es Teams, architektonische Änderungen im Laufe der Zeit zu vergleichen. Es hilft dabei, Fragen wie „Wie hat sich dieses Modul in den letzten beiden Releases verändert?“ zu beantworten.
Integration mit IDEs: Viele moderne Umgebungen bieten Echtzeit-Diagrammierung. Dadurch können Entwickler die Auswirkungen einer Änderung sofort sehen. Diese sind jedoch oft lokal. Für eine sichtbare Zusammenarbeit im Team ist ein zentraler Repository für generierte Diagramme notwendig.
Zukünftige Trends und KI-Integration 🤖
Das Feld entwickelt sich weiter. Die nächste Generation von Werkzeugen integriert künstliche Intelligenz, um die semantische Lücke zu schließen.
- Natürliche Sprachverarbeitung:Zukünftige Werkzeuge könnten Codekommentare und Commit-Nachrichten lesen, um dem Diagramm Kontext hinzuzufügen. Dies könnte Beziehungen basierend auf der in den Code beschriebenen Logik, nicht nur der Syntax, kennzeichnen.
- Mustererkennung:KI kann Designmuster automatisch erkennen. Anstatt nur eine Klasse zu zeichnen, könnte das Werkzeug sie basierend auf der Implementierung als „Beobachter“ oder „Fabrik“ kennzeichnen.
- Prädiktive Analyse: Einige Plattformen beginnen bereits, strukturelle Änderungen vorzuschlagen. Wenn ein Diagramm eine hohe Kopplung zeigt, könnte das Werkzeug vorschlagen, ein Modul zu teilen.
Diese Fortschritte versprechen, über die einfache strukturelle Abbildung hinauszugehen, hin zu architektonischer Intelligenz. Doch das zentrale Prinzip bleibt: Der Code ist die Quelle der Wahrheit.
Häufig gestellte Fragen ❓
Können automatisierte Werkzeuge Microservices bewältigen?
Ja, aber mit Einschränkungen. Die Microservices-Architektur beinhaltet mehrere Repositories. Ein Werkzeug muss konfiguriert werden, um Daten über Dienste hinweg zu aggregieren. Es kann Abhängigkeiten zwischen Diensten anzeigen, kann jedoch die interne Logik jedes Dienstes in einer einzigen Ansicht ohne erhebliche Konfiguration nicht darstellen.
Ist es besser, vor oder nach dem Codieren zu dokumentieren?
Bei automatisierter Generierung kommt der Code zuerst. Man kann kein Diagramm aus nichts generieren. Man kann jedoch ein Diagramm aus einem Skelett- oder Stub-Code generieren, um die beabsichtigte Struktur zu visualisieren, bevor die Logik ausgefüllt wird.
Ersetzt dies die Notwendigkeit eines Softwarearchitekten?
Nein. Es ersetzt die Notwendigkeit eines Dokumentations-Verfassers. Der Architekt ist weiterhin erforderlich, um Muster, Einschränkungen und die Geschäftslogik zu definieren. Das Werkzeug visualisiert lediglich das Ergebnis dieser Entscheidungen.
Wie gehe ich mit proprietären Bibliotheken um?
Automatisierte Werkzeuge haben oft Schwierigkeiten mit proprietären Bibliotheken. Sie können sie als schwarze Kästen behandeln. Sie können das Werkzeug oft so konfigurieren, dass bestimmte Paketnamen als externe Abhängigkeiten behandelt werden, wodurch der Lärm im Diagramm reduziert wird.
Was ist, wenn das Diagramm zu groß ist?
Verwenden Sie Navigation und Filterung. Die meisten Werkzeuge ermöglichen es Ihnen, auf eine Klasse zu klicken, um deren Details anzuzeigen und den Rest zu verbergen. Versuchen Sie nicht, die gesamte Unternehmensarchitektur auf einem Bildschirm unterzubringen. Zerlegen Sie sie nach Domänen.
Abschließende Gedanken 🏁
Die automatisierte Erzeugung von UML-Klassendiagrammen ist eine leistungsstarke Fähigkeit für die moderne Softwareentwicklung. Sie löst das anhaltende Problem der Dokumentationsabweichung und bietet sofortige Sichtbarkeit der Systemstruktur. Sie ist jedoch kein Ersatz für sorgfältige Gestaltung.
Der Erfolg hängt davon ab, das Diagramm als dynamisches Artefakt, das aus dem Code abgeleitet ist, zu betrachten, anstatt als statisches Dokument, das separat gepflegt werden muss. Wenn diese Werkzeuge korrekt in den Entwicklungszyklus integriert sind, fördern sie die Zusammenarbeit und verringern die kognitive Belastung. Sie ermöglichen es Teams, sich auf die Lösung von Problemen zu konzentrieren, anstatt Kästchen zu zeichnen.
Der Schlüssel liegt im Gleichgewicht. Verwenden Sie Automatisierung für die Struktur und menschliches Fachwissen für die Absicht. Zusammen schaffen sie eine robuste architektonische Grundlage, die Wachstum und Veränderung unterstützt.

