










Dans le paysage de l’architecture logicielle, comprendre comment les systèmes fonctionnent physiquement est tout aussi crucial que de comprendre leur structure logique. Le diagramme de déploiement UML agit comme un pont entre la conception abstraite et l’infrastructure concrète. Il cartographie l’architecture physique, en détaillant le matériel, les réseaux et les composants logiciels qui constituent l’environnement d’exécution. Pour les développeurs et les architectes, ce diagramme n’est pas simplement un dessin ; c’est un plan directeur pour la stabilité, la scalabilité et la sécurité. 📈
Créer un modèle précis exige une grande précision. Un diagramme flou entraîne des erreurs de déploiement, des failles de sécurité et des cauchemars de maintenance. Ce guide propose une approche structurée pour modéliser les environnements de déploiement. Il se concentre sur les éléments essentiels, les relations et une checklist rigoureuse afin de garantir que votre documentation architecturale reflète la réalité.
Comprendre les fondations 🧩
Avant de plonger dans la checklist, il est essentiel de comprendre ce qui constitue un diagramme de déploiement. Contrairement aux diagrammes de classe qui se concentrent sur la structure des données, ou aux diagrammes de séquence qui se concentrent sur le comportement, le diagramme de déploiement se concentre surl’exécution physique. Il répond à la question : « Où le logiciel s’exécute-t-il ? »
Ce type de diagramme est particulièrement utile pendant la phase de déploiement du cycle de vie du développement logiciel. Il aide les équipes DevOps, les administrateurs système et les développeurs à s’aligner sur les exigences d’infrastructure. Il visualise :
- La topologie physique du réseau.
- Les ressources matérielles disponibles (serveurs, bases de données, passerelles).
- Les artefacts logiciels déployés sur ces ressources.
- Les chemins de communication entre les composants.
Analyse des éléments fondamentaux 📦
La précision commence par une terminologie correcte. Chaque élément du diagramme a une signification précise. Une étiquette incorrecte sur un artefact ou un nœud peut entraîner des erreurs de configuration dans l’environnement de production.
| Élément | Définition | Représentation visuelle |
|---|---|---|
| Nœud | Une ressource informatique physique. Elle peut être matérielle (serveur, routeur) ou un environnement d’exécution logiciel (conteneur, système d’exploitation). | Forme de cube 3D |
| Artéfact | Une représentation physique d’un composant logiciel. Cela inclut les fichiers exécutables, les bibliothèques, les bases de données ou les fichiers de configuration. | Forme de document |
| Chemin de communication | Le lien entre les nœuds. Il définit le protocole et la bande passante nécessaires pour l’échange de données. | Ligne (pleine ou pointillée) |
| Appareil | Représente généralement un appareil physique tel qu’un ordinateur, un routeur ou un téléphone mobile. | Icône d’appareil |
| Environnement d’exécution | Une plateforme logicielle qui héberge les artefacts, tels qu’une machine virtuelle Java ou un serveur web. | Boîte à l’intérieur d’un nœud |
Comprendre ces distinctions permet d’éviter l’erreur courante de traiter un conteneur logiciel comme un serveur physique. Les deux sont des nœuds, mais ils fonctionnent différemment au sein de la hiérarchie.
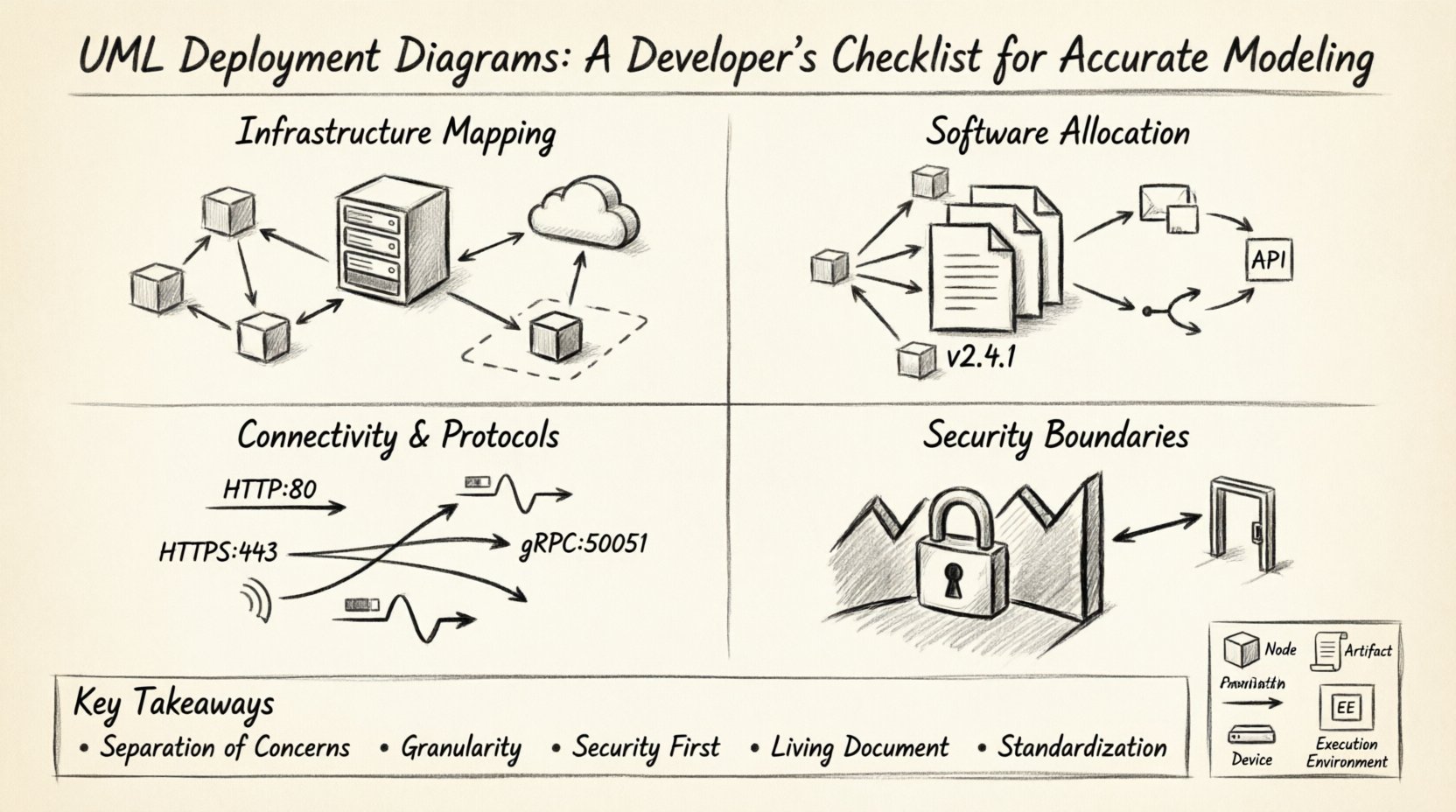
La liste de vérification architecturale ✅
Pour garantir que votre modèle est prêt à être mis en production, vous devez le valider selon un ensemble de critères rigoureux. Cette liste de vérification est conçue pour être utilisée pendant la phase de revue du design. Elle couvre l’infrastructure, l’affectation du logiciel, la connectivité et la sécurité.
1. Cartographie de l’infrastructure 🏗️
La première étape consiste à représenter avec précision l’infrastructure physique ou virtuelle. Ne supposez pas que le schéma correspond au code ; vérifiez-le par rapport aux définitions réelles d’infrastructure en tant que code.
- Identifier tous les nœuds : Liste chaque serveur, instance de base de données et passerelle. Des dispositifs aux bords ou des capteurs IoT sont-ils impliqués ?
- Différencier physique et virtuel : Marquez clairement les machines virtuelles, les conteneurs ou les serveurs sans système d’exploitation. Cette distinction a un impact sur la planification des ressources.
- Étiqueter les spécifications matérielles : Inclure les exigences en CPU, mémoire et stockage sur les nœuds de haut niveau. Cela aide à la planification de la capacité.
- Segments réseau : Définissez les limites du réseau. Les nœuds se trouvent-ils dans un DMZ, une sous-réseau privé ou une région de cloud public ?
- Redondance : Le schéma montre-t-il des nœuds de basculement ? Un point unique de défaillance sur le schéma doit être signalé comme un risque.
2. Affectation du logiciel 👨💻
Une fois l’infrastructure matérielle définie, le logiciel doit être placé correctement. Cette section garantit que le code s’exécute là où il est prévu.
- Cartographier les artefacts sur les nœuds : Chaque fichier exécutable, script ou bibliothèque doit être attaché à un nœud spécifique. Évitez les artefacts flottants.
- Environnements d’exécution : Assurez-vous que le nœud prend en charge l’artefact. Si un nœud est étiqueté comme serveur Linux, vérifiez que l’artefact ne nécessite pas spécifiquement Windows.
- Contrôle de version : Notez la version du logiciel en cours d’exécution sur chaque nœud. Des nœuds différents peuvent exécuter des versions différentes pendant une phase de migration.
- Middleware : Identifiez tout middleware requis, tel que des files de messages, des couches de mise en cache ou des passerelles API. Ce sont des artefacts critiques.
- Fichiers de configuration : Ne négligez pas les artefacts de configuration. Les paramètres spécifiques à l’environnement (dev, staging, prod) doivent être visibles ou référencés.
3. Connectivité et protocoles 🔄
La communication est le sang vital d’un système distribué. Les lignes reliant vos nœuds transportent bien plus que des données ; elles comportent des implications en matière de sécurité et des contraintes de performance.
- Spécifiez les protocoles :Ne vous contentez pas de tracer une ligne. Étiquetez-la. S’agit-il d’HTTP, HTTPS, gRPC, AMQP ou TCP ? Le protocole détermine la sécurité et les performances.
- Numéros de port :Pour les infrastructures critiques, indiquez les numéros de port. Cela facilite la configuration des pare-feu.
- Directionnalité :Utilisez des flèches pour indiquer le sens du flux de données. La base de données est-elle en lecture seule pour ce nœud ? Le client envoie-t-il des données vers le serveur ?
- Bande passante :Pour les systèmes à fort trafic, indiquez la bande passante requise. Cela évite les goulets d’étranglement réseau.
- Contraintes de latence :Si un traitement en temps réel est requis, indiquez les attentes de latence entre les nœuds.
4. Frontières de sécurité 🔒
La sécurité doit être modélisée visuellement. Un diagramme de déploiement qui ignore les zones de sécurité est incomplet.
- Pare-feux :Tracez des pare-feux entre les réseaux fiables et non fiables. Montrez où le trafic est inspecté.
- Zones de chiffrement :Mettez en évidence les zones où les données doivent être chiffrées au repos ou en transit.
- Points d’authentification :Où a lieu l’authentification ? Au niveau de la passerelle, de l’application ou de la base de données ?
- Contrôle d’accès :Indiquez quels nœuds ont accès aux nœuds contenant des données sensibles. Tous les serveurs web ne doivent pas communiquer directement avec la base de données centrale.
- Conformité :Si des réglementations exigent que les données restent dans une région spécifique, marquez cette région sur le diagramme.
Gestion de la complexité 🧱
À mesure que les systèmes grandissent, les diagrammes de déploiement peuvent devenir accablants. Un seul diagramme montrant chaque microservice, base de données et équilibreur de charge à travers une infrastructure mondiale est illisible. Vous devez gérer la complexité par abstraction.
1. Modélisation hiérarchique
Utilisez une approche par couches. Commencez par une vue d’ensemble montrant les régions majeures et les chemins critiques. Ensuite, créez des sous-diagrammes pour des clusters ou services spécifiques. Cela maintient le diagramme principal propre tout en conservant les détails là où ils sont nécessaires.
- Vue globale :Montrez les centres de données, les régions cloud et les passerelles majeures.
- Vue du cluster : Zoom sur un cluster Kubernetes ou une ferme de serveurs spécifique.
- Vue Service : Descendez dans le détail d’un déploiement de microservice spécifique.
2. Agrégation
Regroupez les nœuds similaires. Si vous avez 50 serveurs web identiques, ne dessinez pas 50 nœuds distincts. Dessinez un seul nœud étiqueté « Cluster de serveurs web (50 instances) ». Cela réduit le bruit visuel tout en conservant une précision concernant la capacité.
3. Normalisation
Établissez une convention de nommage pour tous les nœuds et les artefacts. Utilisez des préfixes tels que « DB- », « APP- » ou « GW- ». La cohérence réduit la charge cognitive lors de la lecture du diagramme. Évitez les noms ambigus tels que « Serveur1 » ou « Boîte principale ».
Erreurs courantes de modélisation ⛔
Même les architectes expérimentés commettent des erreurs. Reconnaître ces pièges tôt permet d’économiser un temps considérable lors de la mise en œuvre.
- Mélange entre logique et physique : Ne placez pas les classes logicielles sur un nœud de déploiement. Gardez le diagramme de classe séparé. Le diagramme de déploiement concerne les fichiers et les machines, et non les objets et les méthodes.
- Ignorer la latence réseau : Supposer que tous les nœuds sont connectés via un LAN local. Dans les environnements cloud, les nœuds situés dans des régions différentes présentent une latence importante.
- Passer à côté des dépendances : Oublier de modéliser les dépendances entre les artefacts. Si l’artefact A a besoin de l’artefact B pour démarrer, cette relation doit être claire.
- État statique : Traiter le diagramme comme un dessin unique. Les systèmes évoluent. Un diagramme non mis à jour devient trompeur.
- Interfaces externes manquantes : Oublier les services tiers. Si votre application appelle une passerelle de paiement externe, ce nœud externe doit être représenté.
Intégration avec d’autres modèles 🤖
Un diagramme de déploiement n’existe pas en isolation. Il interagit avec d’autres diagrammes UML pour fournir une image complète du système.
1. Avec les diagrammes de classes
Le diagramme de classes définit la structure interne du logiciel. Le diagramme de déploiement définit où ce logiciel est hébergé. Assurez-vous que les composants du diagramme de classes sont représentés comme des artefacts dans le diagramme de déploiement. Cette traçabilité garantit que le code correspond au plan d’infrastructure.
2. Avec les diagrammes de séquence
Les diagrammes de séquence montrent le flux des messages. Le diagramme de déploiement fournit le contexte de ces messages. Si un diagramme de séquence montre un message provenant de « Client » vers « Serveur », le diagramme de déploiement doit montrer le chemin physique suivi par ce message.
3. Avec les diagrammes d’activité
Les diagrammes d’activité montrent le flux de travail. Le diagramme de déploiement montre les ressources nécessaires pour exécuter ce flux. Par exemple, si un diagramme d’activité montre une étape « Traiter une image », le diagramme de déploiement doit montrer la GPU ou le nœud de calcul capable d’effectuer cette tâche.
Maintenance et évolution 🔄
Le logiciel n’est jamais statique. Au fur et à mesure que les exigences évoluent, l’infrastructure évolue également. Le diagramme de déploiement doit évoluer en parallèle avec le code source.
- Gestion des versions : Traitez le diagramme comme du code. Stockez-le dans un système de gestion de version. Cela vous permet de revenir à des états antérieurs si un déploiement échoue.
- Mises à jour automatiques : Là où c’est possible, générez le diagramme à partir du code d’infrastructure. Des outils peuvent analyser les modèles Terraform ou CloudFormation pour mettre à jour automatiquement le diagramme.
- Cycles de revue : Intégrez les mises à jour du diagramme au processus de revue du code. Si l’infrastructure change, le diagramme doit être mis à jour avant la fusion.
- Liens vers la documentation : Liez le diagramme aux procédures opérationnelles. Si un nœud est marqué comme « critique », liez-le au plan de récupération après sinistre.
- Alignement des parties prenantes : Revoyez régulièrement le diagramme avec les équipes opérationnelles. Elles connaissent mieux l’infrastructure que les développeurs. Leur retour garantit que le modèle reste précis.
Conclusion 🏁
La création d’un diagramme de déploiement UML est un exercice de clarté et de précision. Elle exige une compréhension approfondie à la fois du logiciel en cours de construction et de l’environnement dans lequel il fonctionnera. En suivant une checklist structurée, en évitant les pièges courants et en maintenant le modèle dans le temps, vous créez un actif précieux pour votre équipe.
Ce diagramme sert de source unique de vérité pour l’infrastructure. Il réduit l’ambiguïté entre développement et opérations. Il empêche le décalage de configuration. Et en fin de compte, il garantit que le système que vous construisez fonctionne de manière fiable dans le monde réel. Investissez le temps à modéliser avec précision, et le processus de déploiement deviendra plus fluide et plus prévisible.
Souvenez-vous, l’objectif n’est pas seulement de dessiner une image. L’objectif est de communiquer la réalité physique de votre système. Utilisez la checklist fournie ici pour valider votre travail. Assurez-vous que chaque nœud, artefact et connexion est pris en compte. Avec un modèle de déploiement solide, vous posez les bases d’une architecture résiliente et évolutif.
Points clés 👏
- Séparation des préoccupations : Maintenez la conception logique séparée du déploiement physique.
- Granularité : Utilisez la hiérarchie pour gérer la complexité sans perdre de détails.
- Sécurité en priorité : Modélisez toujours les frontières et les zones de chiffrement.
- Document vivant : Mettez à jour le diagramme chaque fois que l’infrastructure change.
- Standardisation : Utilisez des noms et des symboles cohérents pour plus de clarté.

