











Dans le paysage complexe de l’ingénierie logicielle moderne, la séparation entre le code et l’infrastructure s’est estompée. Les développeurs full-stack ne rédigent plus la logique en isolation ; ils conçoivent des écosystèmes. Au sein de cet écosystème, un diagramme de déploiement sert de plan de réalité. Il traduit le code abstrait en infrastructure concrète, définissant où le logiciel vit, comment il communique et comment il survit. Bien qu’il soit souvent négligé au profit des diagrammes de séquence ou de composants, le diagramme de déploiement fournit le contexte essentiel requis pour la stabilité et la scalabilité.
Comprendre la topologie physique et logique d’une application n’est pas simplement un exercice de documentation. C’est une exigence fondamentale pour un dépannage efficace, une vérification de sécurité et une planification de capacité. Ce guide explore la nécessité structurelle des diagrammes de déploiement, en allant au-delà des définitions basiques pour examiner comment ils agissent comme des actifs opérationnels au sein d’un environnement full-stack.
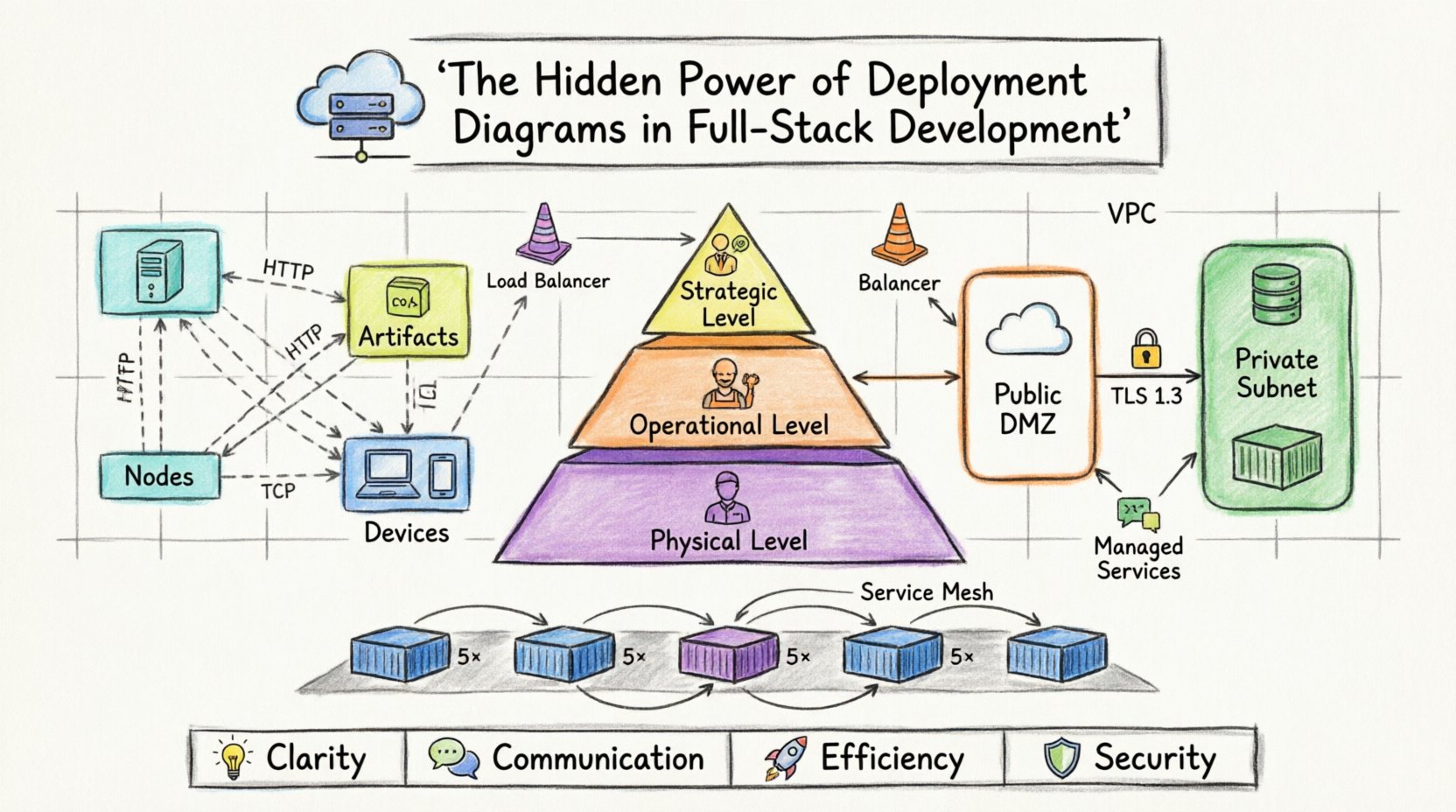
🧩 Définition du diagramme de déploiement dans son contexte
Un diagramme de déploiement est une représentation visuelle de l’architecture physique d’un système logiciel. Il associe les artefacts logiciels aux nœuds matériels. Contrairement à un diagramme de classes, qui se concentre sur les structures internes des objets, ou à un diagramme de séquence, qui se concentre sur les interactions temporelles, un diagramme de déploiement se concentre sur la localisation et la connectivité.
Dans un environnement full-stack, cette distinction est vitale. Le frontend, l’API backend, la base de données et les couches de mise en mémoire tampon résident souvent sur des machines différentes ou dans des frontières logiques distinctes. Le diagramme de déploiement illustre ces frontières.
Éléments fondamentaux du diagramme
Pour comprendre l’utilité de ces diagrammes, il faut d’abord identifier les composants standards utilisés pour les construire :
- Nœuds :Représentent les ressources informatiques physiques. Il peut s’agir de serveurs, de périphériques ou d’environnements d’exécution. Un nœud est le conteneur des artefacts.
- Artefacts :Les composants logiciels qui sont déployés. Cela inclut les exécutables, les bibliothèques, les schémas de base de données ou les images conteneurs.
- Connexions :Les canaux de communication entre les nœuds. Ils représentent des protocoles réseau, tels que HTTP, TCP/IP ou les pilotes de base de données.
- Périphériques :Matériel utilisé par les utilisateurs finaux, tels que des postes de travail, des téléphones portables ou des tablettes, souvent inclus pour montrer le point d’entrée dans le système.
En cartographiant ces éléments, les équipes acquièrent une compréhension spatiale de l’application. Cette compréhension spatiale fait la différence entre deviner où une panne pourrait survenir et la diagnostiquer de manière systématique.
🌐 Pourquoi les équipes full-stack ont besoin de cette visualisation
Le développement full-stack implique la responsabilité de toute la pile, depuis l’interface client jusqu’à la couche de persistance des données. Cette responsabilité engendre un fort risque de dérive architecturale. Sans diagramme de déploiement, le modèle mental de l’infrastructure détenue par les différents membres de l’équipe peut diverger. Un ingénieur pourrait supposer que la base de données est sur le même hôte que le serveur d’application, tandis qu’un autre pourrait supposer qu’elle est sur un cluster distinct.
Scénarios où le diagramme ajoute de la valeur
- Intégration des nouveaux ingénieurs :Les nouveaux membres de l’équipe peuvent comprendre immédiatement la topologie du système sans avoir à fouiller dans les fichiers de configuration ou les paramètres de console cloud.
- Planification de capacité :Visualiser l’allocation des ressources aide à identifier les goulets d’étranglement. Si un seul nœud gère tout le trafic pour un service spécifique, le diagramme met en évidence ce point de défaillance unique.
- Vérifications de sécurité :Les diagrammes clarifient les zones réseau. Ils montrent où se trouvent les données sensibles et comment elles sont accessibles depuis des environnements externes.
- Planification de migration :Lors du passage d’une infrastructure locale à une infrastructure cloud, ou entre des fournisseurs de cloud, le diagramme sert de spécification de l’état cible.
🗺️ Cartographie de la topologie de l’infrastructure
L’erreur la plus courante lors de la création de diagrammes de déploiement est d’essayer de dessiner chaque serveur existant. Cela entraîne un encombrement et réduit la lisibilité. En revanche, les diagrammes doivent se concentrer sur des regroupements logiques et des frontières fonctionnelles.
Niveaux d’abstraction
Les différents intervenants ont besoin de niveaux de détail différents. Un CTO doit voir la répartition des coûts et des emplacements au niveau élevé. Un ingénieur DevOps doit voir les ports réseau et les instances de service. Une stratégie de déploiement doit tenir compte de ces niveaux.
| Niveau du diagramme | Public cible | Granularité des détails | Focus principal |
|---|---|---|---|
| Stratégique | Direction, architectes | Élevé | Coûts, régions, haute disponibilité |
| Opérationnel | DevOps, SRE | Moyen | Instances de service, équilibreurs de charge, protocoles |
| Physique | Ingénieurs d’infrastructure | Faible | Adresses IP, spécifications matérielles, emplacements des baies |
Utiliser ces niveaux évite le surcroît d’information. Le niveau opérationnel est généralement le point idéal pour le développement full-stack, en équilibrant les détails techniques et la vue stratégique.
Représentation de l’infrastructure cloud
Le développement moderne implique rarement des serveurs physiques. La plupart des systèmes fonctionnent sur une infrastructure cloud. Lors de la création de diagrammes de déploiement pour des environnements cloud, il est crucial de représenter des regroupements logiques plutôt que des identifiants d’instance spécifiques.
- Clouds privés virtuels (VPC) : Représentés sous forme de grands conteneurs englobant les ressources internes.
- Équilibreurs de charge : Essentiels pour répartir le trafic. Ils doivent être clairement marqués comme points d’entrée.
- Services gérés : Les bases de données, les files d’attente et les compartiments de stockage existent souvent en dehors des nœuds d’application. Ils doivent être dessinés comme des nœuds externes connectés via des protocoles spécifiques.
🔒 Visualisation du flux de données et de la sécurité
Un diagramme de déploiement ne concerne pas seulement l’emplacement du logiciel ; il concerne aussi le déplacement des données entre ces emplacements. Dans une application full-stack, les données circulent du client, à travers le réseau, vers le backend, puis vers le stockage. Visualiser ce flux est essentiel pour la conformité en matière de sécurité.
Définition des frontières de confiance
La sécurité repose sur des frontières de confiance. Un diagramme de déploiement rend ces frontières visibles. Par exemple, la connexion entre un périphérique client et le serveur d’application est publique. La connexion entre le serveur d’application et la base de données est privée.
- ZDM (Zone démilitarisée) :Les services exposés à internet doivent être isolés des services internes.
- Sous-réseaux internes :Les serveurs de base de données et les nœuds de cache doivent résider dans des sous-réseaux non directement accessibles depuis internet.
- Chiffrement :Les connexions traversant des frontières de confiance doivent être signalées comme chiffrées.
En marquant ces frontières sur le diagramme, les équipes de sécurité peuvent rapidement vérifier que l’architecture est conforme aux exigences de conformité. Si un nœud de base de données est directement connecté à internet sur le diagramme, cela signale immédiatement un risque de sécurité.
📦 Gestion de la complexité dans les microservices
Le passage vers une architecture de microservices a considérablement compliqué les diagrammes de déploiement. Dans un système monolithique, un artefact pourrait se trouver sur un seul nœud. Dans un système de microservices, des dizaines d’artefacts pourraient être répartis sur des dizaines de nœuds.
Gestion de l’échelle dans les diagrammes
Lorsque le nombre de nœuds dépasse une limite visuelle gérable, des techniques d’abstraction deviennent nécessaires.
- Regroupement :Utilisez des dossiers ou des conteneurs pour regrouper les services liés. Par exemple, un conteneur « Service de paiement » pourrait contenir l’API, le worker et la base de données.
- Symboles de réplication :Indiquez qu’un nœud est répliqué sans dessiner chaque instance individuelle. Utilisez une notation de multiplicité pour indiquer « 5+ instances ».
- Agrégation :Regroupez plusieurs nœuds similaires sous un seul nom logique, par exemple « Nœuds de travail ».
Cette approche maintient le diagramme lisible tout en préservant la vérité de l’architecture. Elle permet à l’équipe de voir qu’il y a cinq nœuds de travail sans encombrer le canevas avec cinq boîtes distinctes.
Considérations relatives au service mesh
Dans les configurations avancées, un service mesh gère la communication entre les services. Bien que le mesh lui-même soit de l’infrastructure, il influence la manière dont les services communiquent entre eux. Le diagramme de déploiement doit indiquer la présence d’une couche de mesh, même si la logique interne de routage est abstraite.
- Représentez le mesh comme une couche distincte entre les services.
- Notez que le trafic passe par le mesh pour être observé et soumis à des politiques.
- Précisez que le mesh gère les réessais, les délais d’attente et la coupure de circuit.
Cette distinction aide les développeurs à comprendre que le protocole de communication pourrait être le mTLS (TLS mutuel) plutôt que le HTTP standard, ce qui influence la manière dont ils déboguent les problèmes réseau.
🔄 Intégration avec les flux opérationnels
Un diagramme de déploiement qui reste dans un document statique est une ressource perdue. Il doit être intégré au flux de travail de l’équipe pour rester pertinent.
Contrôle de version pour l’infrastructure
Tout comme le code source est versionné, les diagrammes doivent être traités comme du code. Les modifications de la topologie de l’infrastructure doivent déclencher des mises à jour du diagramme.
- Messages de validation : Lorsqu’un développeur ajoute un nouveau cluster de base de données, le commit doit faire référence au diagramme mis à jour.
- Processus de revue :Les diagrammes doivent être revus conjointement avec les demandes de fusion qui affectent l’infrastructure.
- Documentation :Liez la version du diagramme à l’étiquette de version spécifique dans le dépôt.
Cette pratique garantit que le diagramme n’est jamais à plus d’un commit derrière l’état réel du système. Elle crée une source unique de vérité qui évolue avec le produit.
Alignement du pipeline CI/CD
Le pipeline d’intégration continue et de déploiement continu est le moteur qui déplace les artefacts vers les nœuds indiqués sur le diagramme. La configuration du pipeline doit correspondre au diagramme.
- Mappage des environnements :Si le diagramme montre les environnements Dev, Staging et Prod, le pipeline doit avoir des étapes distinctes pour chacun.
- Propagation des artefacts :La même version d’artefact doit traverser les nœuds du diagramme de manière séquentielle.
- Plans de retour arrière :Le diagramme doit indiquer quels nœuds sont revenus en arrière en cas d’échec.
Aligner le pipeline avec le diagramme réduit le risque de dérive de configuration. Cela garantit que le système automatisé ne fait pas quelque chose de différent de ce que dit la documentation.
🛠️ Erreurs courantes et corrections
Même les architectes expérimentés commettent des erreurs en dessinant ces diagrammes. Reconnaître les pièges courants aide à maintenir l’exactitude.
1. Surconception de la mise en page
Passer trop de temps à aligner parfaitement les boîtes détourne l’attention du contenu. L’objectif est la communication, pas l’art. Utilisez des formes standard et laissez des espaces blancs pour plus de clarté.
2. Ignorer la latence
Si deux services sont sur des nœuds différents dans des régions différentes, la connexion présentera une latence. Le diagramme devrait idéalement indiquer la région ou la distance réseau si cela affecte les performances.
3. Points de défaillance manquants
Un diagramme montrant uniquement les chemins de succès est trompeur. Il est utile d’indiquer où une connexion pourrait échouer. Par exemple, si une connexion à la base de données dépend d’un commutateur réseau spécifique, ce commutateur doit être visible comme une dépendance.
4. Protocoles obsolètes
De nombreux systèmes utilisent encore des protocoles hérités, mais les nouveaux sont plus rapides. Assurez-vous que les étiquettes de connexion reflètent l’implémentation actuelle. N’écrivez pas « HTTP » si la connexion est en réalité « gRPC » ou « WebSocket ».
🔮 Architecture résiliente à l’avenir
La technologie évolue. De nouveaux protocoles apparaissent, et les modèles d’infrastructure évoluent. Un diagramme de déploiement doit être suffisamment souple pour s’adapter à ces changements sans nécessiter un redessin complet.
Concentrez-vous sur la logique, pas sur le matériel
Au lieu de dessiner un modèle spécifique de serveur, dessinez un « nœud de calcul ». Au lieu de dessiner un moteur de base de données spécifique, dessinez un « magasin de données ». Cela permet au matériel sous-jacent de changer sans compromettre la validité du diagramme.
- Nœuds logiques : Concentrez-vous sur le rôle (par exemple, « passerelle API ») plutôt que sur l’hôte spécifique.
- Artifacts génériques : Décrivez la fonction logicielle plutôt que le nom spécifique du binaire.
- Indifférence au protocole : Lorsque c’est possible, décrivez l’échange de données plutôt que le numéro de port spécifique.
Cette approche prolonge la durée de vie de la documentation. Une équipe peut passer d’une plateforme d’orchestration de conteneurs à une autre sans avoir à mettre à jour le diagramme, à condition que la topologie logique reste identique.
🤝 Sessions de conception collaborative
La création d’un diagramme de déploiement est souvent une démarche collective. Elle nécessite des contributions des ingénieurs backend, des ingénieurs frontend et des spécialistes de l’infrastructure. Utiliser un outil collaboratif pour ce processus garantit un consensus.
Structure du atelier
- Premier brouillon : L’architecte principal établit un brouillon sommaire sur la base des exigences.
- Tour de revue : Les ingénieurs backend vérifient les rôles des serveurs et les connexions à la base de données.
- Validation frontend : Les ingénieurs frontend confirment les points d’entrée et les exigences côté client.
- Approbation finale : L’équipe infrastructure valide les zones réseau et de sécurité.
Ce processus collaboratif réduit les silos. Il garantit que chacun comprend les contraintes et les capacités du système avant d’écrire une seule ligne de code.
📉 Le coût des diagrammes manquants
Que se passe-t-il lorsque une équipe fonctionne sans diagramme de déploiement ? Les conséquences sont souvent subtiles mais coûteuses.
- Temps de débogage : Les ingénieurs passent des heures à tracer manuellement les chemins réseau au lieu de consulter un diagramme.
- Décalage de configuration : Les équipes apportent des modifications dans la console cloud qui ne sont pas documentées, entraînant des écarts entre le système et la documentation.
- Perte de connaissances : Lorsqu’un ingénieur senior quitte, la topologie de l’infrastructure devient un mystère pour l’équipe restante.
- Failles de sécurité : L’accès public non intentionnel aux services internes passe inaperçu parce que l’architecture n’a pas été visualisée.
Le coût de création et de maintenance du diagramme est nettement inférieur au coût de résolution des problèmes causés par son absence.
📝 Résumé des avantages
Les diagrammes de déploiement ne sont pas des éléments facultatifs ; ils constituent des composants essentiels d’une pratique d’ingénierie mûre. Ils apportent de la clarté au sein de la complexité, assurent l’alignement en matière de sécurité et facilitent la collaboration entre les disciplines.
En se concentrant sur des regroupements logiques, en maintenant un contrôle de version et en intégrant les diagrammes aux flux opérationnels, les équipes peuvent tirer un maximum de valeur de ces diagrammes. L’investissement dans la documentation porte ses fruits en termes de stabilité du système et de vitesse de développement.
Pour les développeurs full-stack, maîtriser l’art de la visualisation du déploiement est une compétence essentielle. Elle comble le fossé entre le code et la réalité, garantissant que le logiciel que vous construisez peut survivre dans le monde réel.
- Clarté : Élimine toute ambiguïté concernant la topologie du système.
- Communication : Fournit un langage commun à tous les membres de l’équipe.
- Efficacité : Réduit le temps consacré au dépannage des problèmes d’infrastructure.
- Sécurité : Met en évidence les frontières de confiance et les risques réseau.
Commencez par documenter votre état actuel. Identifiez les nœuds, les artefacts et les connexions. Une fois la base établie, vous pouvez commencer à optimiser, à scaler et à sécuriser votre architecture avec confiance.

