











Dans le paysage du développement logiciel, la clarté est une monnaie. Les architectes et les développeurs s’appuient sur des modèles visuels pour comprendre des systèmes complexes. Parmi les spécifications du langage de modélisation unifiée (UML), le diagramme de classes se distingue comme fondement de la conception orientée objet. Traditionnellement, la création de ces diagrammes nécessitait un effort manuel, souvent entraînant une documentation qui restait en retard par rapport au code. L’introduction des outils de génération automatisée a transformé ce paradigme. Ce guide examine les réalités techniques, les avantages et les limites de la génération automatique des diagrammes de classes UML.
Comprendre les compromis est essentiel pour préserver l’intégrité architecturale. Bien que l’automatisation accélère la documentation, elle ne remplace pas la réflexion de conception. Cet article explore les mécanismes de conversion du code en diagramme, la fidélité de la sortie, et la manière dont les équipes peuvent intégrer ces outils dans leurs flux de travail existants sans compromettre la qualité.
Définition de la génération automatisée UML 🛠️
La génération automatisée UML désigne le processus par lequel des outils logiciels extraient directement des informations structurelles à partir du code source pour produire une représentation visuelle. Au lieu de dessiner manuellement des boîtes et des lignes, l’outil analyse le code source, identifie les classes, les interfaces et les hiérarchies d’héritage, puis les associe aux symboles UML.
Ce processus repose sur une analyse statique. L’outil lit l’Arbre Syntaxique Abstrait (AST) du langage de programmation. Il ne fait pas exécuter le code, mais analyse les définitions. Cette distinction est cruciale. Le diagramme reflète la structure statique, et non le comportement à l’exécution. Par exemple, il montre que la classe A hérite de la classe B, mais ne montre pas l’état dynamique d’une instance de A lors d’une opération spécifique.
L’objectif principal est de combler le fossé entre l’implémentation et la documentation. Dans de nombreux projets, la documentation devient obsolète peu après le lancement. La génération automatisée vise à maintenir le modèle synchronisé avec le code source, réduisant ainsi la charge de maintenance liée au maintien des diagrammes à jour.
Mécanismes : Ingénierie avant versus ingénierie inverse 🔄
La génération automatisée relève généralement de deux catégories selon le sens du flux de travail. Comprendre cette différence aide les équipes à choisir l’approche adaptée à leur cycle de vie de projet.
1. Ingénierie avant (code vers diagramme)
L’ingénierie avant consiste à prendre un code existant et à produire un diagramme. C’est la forme la plus courante d’automatisation. Elle est généralement utilisée pour :
- Intégration :Les nouveaux développeurs doivent comprendre rapidement la base de code.
- Refactoring :Les architectes visualisent l’impact des changements structurels avant de les appliquer.
- Systèmes hérités :Les projets sans documentation nécessitent une visualisation immédiate pour commencer la maintenance.
L’outil analyse le dépôt, identifie les définitions de classes et construit le graphe. Il associe les méthodes et les attributs aux modificateurs de visibilité (public, privé, protégé). Toutefois, cela dépend que le code soit bien structuré. Si les noms de variables sont obscurs, le diagramme reflétera cette obscurité.
2. Ingénierie inverse (diagramme vers code)
L’ingénierie inverse prend un modèle visuel et génère des squelettes de code. Bien que moins courante dans les environnements agiles modernes, elle sert des objectifs spécifiques :
- Prototype :Concevoir la structure avant d’écrire la logique d’implémentation.
- Standardisation :Assurer que le nouveau code respecte les modèles architecturaux établis.
- Migration :Convertir des conceptions d’un langage à un autre.
Cette approche exige que l’outil interprète l’intention du diagramme. Les ambiguïtés du modèle visuel peuvent entraîner des squelettes de code génériques nécessitant un raffinement manuel important. C’est un point de départ, et non un produit fini.
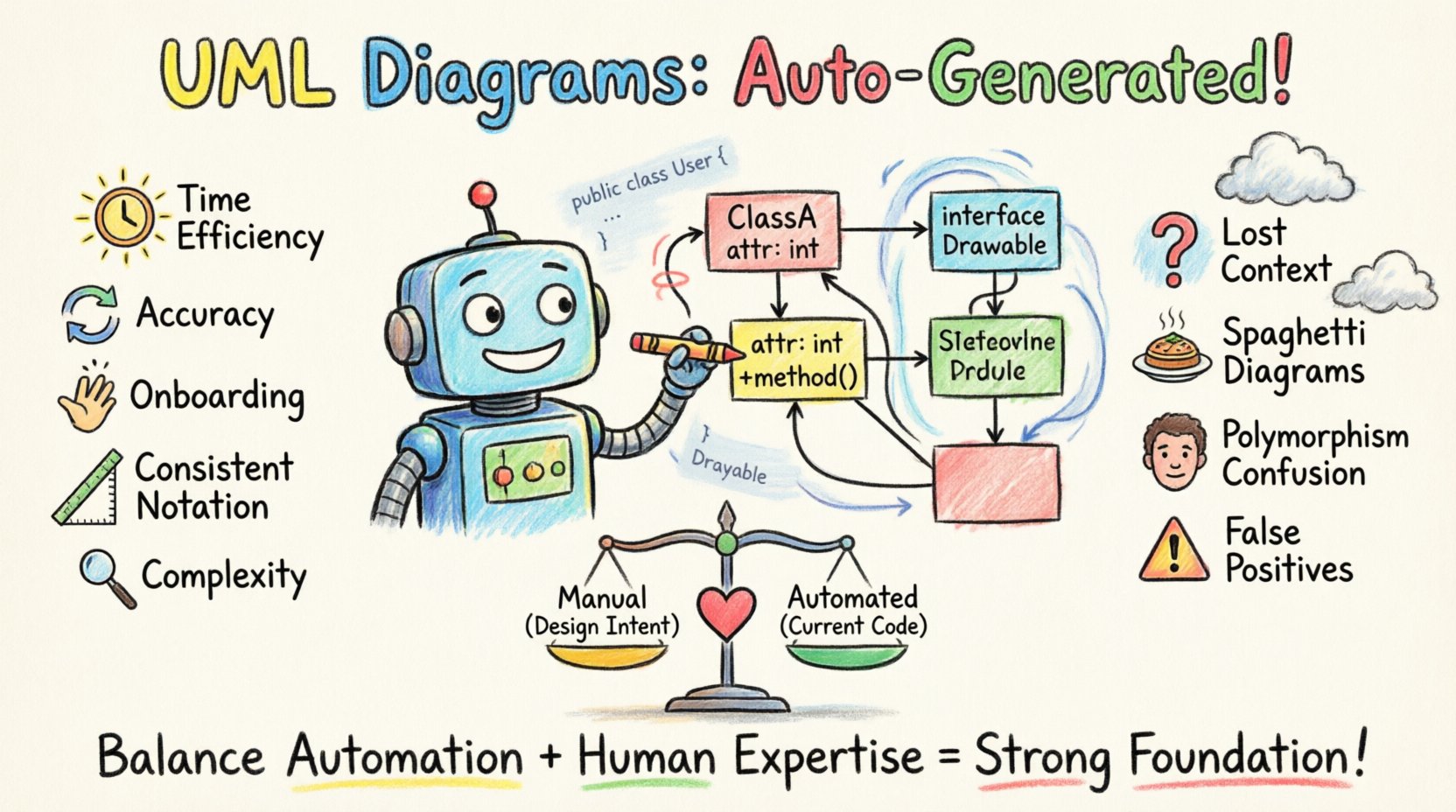
Les avantages de l’automatisation 📈
Pourquoi les équipes investissent-elles dans ces outils ? Les bénéfices sont tangibles et entraînent souvent des gains d’efficacité. La valeur principale réside dans la synchronisation et la visibilité.
- Efficacité du temps : Dessiner manuellement un diagramme pour une application d’entreprise de grande taille peut prendre des semaines. Les outils automatisés génèrent le croquis initial en quelques minutes. Cela permet aux architectes de se concentrer sur la conception de haut niveau plutôt que de dessiner des rectangles.
- Précision et synchronisation : Les diagrammes manuels s’écartent. Lorsqu’un développeur ajoute une méthode, le diagramme ne se met pas à jour jusqu’à ce qu’une personne se souvienne de le modifier. Les outils automatisés reflètent l’état actuel du dépôt. Cela réduit le risque de prendre des décisions fondées sur des informations obsolètes.
- Accélération de l’intégration : Visualiser le graphe des dépendances aide les nouveaux embauchés à comprendre la topologie du système. Il met en évidence les couplages complexes qui pourraient être cachés dans des structures de répertoires profondes.
- Consistance dans la notation : Les outils imposent les conventions standard UML. Il n’y a aucune variation dans la façon dont l’héritage est dessiné ou les associations sont étiquetées. Cela crée un langage commun pour l’équipe.
- Identification de la complexité : Les outils calculent souvent des métriques en parallèle avec le diagramme, telles que la complexité cyclomatique ou la profondeur de couplage. Ces métriques mettent en évidence les classes qui sont trop grandes ou trop dépendantes des autres.
Les défis et limites 📉
Malgré les avantages, l’automatisation n’est pas une solution miracle. Il existe des contraintes techniques et pratiques importantes que les équipes doivent reconnaître pour éviter la frustration.
- Perte du contexte sémantique : Le code contient de la logique, mais les diagrammes montrent la structure. Un diagramme ne peut pas expliquer pourquoi une classe existe ou les règles métier spécifiques qu’elle impose. La nuance de l’implémentation se perd dans l’abstraction.
- Interface vs. Implémentation : Les outils automatisés ont souvent du mal à distinguer entre le contrat (interface) et la réalisation (implémentation). Ils peuvent afficher toutes les méthodes, encombrant ainsi la vue avec du code boilerplate qui n’apporte rien à la compréhension architecturale.
- Gestion du polymorphisme : Le typage dynamique et le polymorphisme à l’exécution sont difficiles à représenter de manière statique. Un diagramme peut montrer une classe parente, mais la classe enfant spécifique utilisée en production dépend de la configuration ou des conditions d’exécution. La vue statique peut être trompeuse.
- Résolution des dépendances : Dans les systèmes monolithiques de grande taille, le diagramme peut devenir un désordre « spaghetti ». Si l’outil ne filtre pas les vues, un seul écran peut afficher des milliers de classes et de lignes. Cela contredit l’objectif de simplification.
- Faux positifs dans la conception : Les outils ne peuvent pas valider les schémas de conception. Ils dessineront une classe comme « singleton » si le code le suggère, mais ils ne peuvent pas vérifier si le schéma a été correctement implémenté ou s’il s’agit d’un anti-schéma.
- Décalage avec le contrôle de version : Si l’outil n’est pas intégré au pipeline de construction, le diagramme généré pourrait être obsolète. Compter sur un fichier statique généré il y a des mois constitue un risque.
Analyse comparative : manuel vs. automatisé ⚖️
Pour clarifier les compromis, considérez la comparaison suivante des caractéristiques entre la création traditionnelle manuelle et la génération automatisée.
| Fonctionnalité | Création manuelle | Génération automatisée |
|---|---|---|
| Vitesse | Lent (heures/jours) | Rapide (minutes) |
| Précision | Élevée (par intention) | Élevée (code actuel) |
| Maintenance | Grand effort | Faible effort |
| Contexte | Élevée (intention de conception) | Faible (structure uniquement) |
| Consistance | Variable (erreur humaine) | Élevée (norme outil) |
| Coût | Élevé (main-d’œuvre) | Moyen (outillage) |
Le tableau met en évidence que le choix n’est pas binaire. Il s’agit d’équilibrer l’intention avec la réalité. Les diagrammes manuels capturent le conception. Les diagrammes automatisés capturent le code.
Mise en œuvre stratégique dans les flux de travail 🚀
Intégrer la génération automatisée exige un changement de processus. Ce n’est pas seulement une installation d’outil ; c’est un changement de flux de travail. Pour réussir, les équipes doivent envisager les stratégies suivantes.
- Intégration avec CI/CD : Le processus de génération des diagrammes doit faire partie du pipeline d’intégration continue. À chaque fusion de code, le diagramme doit être régénéré. Cela garantit que l’artefact dans le dépôt est toujours à jour.
- Filtrage des vues : Ne pas tout injecter dans une seule vue. Créer des vues filtrées basées sur des sous-systèmes, des modules ou des couches. Cela maintient les diagrammes lisibles et centrés sur la portée pertinente.
- Hygiène de la documentation : Établir une règle selon laquelle les diagrammes sont des artefacts générés. Ne pas modifier manuellement les fichiers de diagrammes exportés. Si une modification est nécessaire dans le modèle, mettre à jour le code ou la configuration, puis régénérer. Cela évite la « documentation fantôme » qui diverge de la réalité.
- Automatisation sélective : Toutes les classes n’ont pas besoin d’apparaître dans chaque diagramme. Utilisez des annotations ou des fichiers de configuration pour exclure le code de test, le code généré ou les bibliothèques utilitaires qui ajoutent du bruit.
- Formation : Assurez-vous que l’équipe sait lire les diagrammes générés. Les sorties automatisées peuvent être très denses. Les développeurs doivent savoir naviguer dans la hiérarchie et interpréter les relations.
Considérations sur la maintenance et l’évolution 🧩
Même avec l’automatisation, une maintenance est nécessaire. Le diagramme est une réflexion du code, et le code évolue. Les équipes doivent gérer le cycle de vie du modèle visuel.
Détérioration du code : Au fil du temps, la dette technique s’accumule. Les outils automatisés documenteront fidèlement cette dette. Si une classe devient trop complexe, le diagramme le montrera. Cela peut servir de signal pour refactoriser. Le diagramme devient un outil de diagnostic.
Gestion de versions : Lors de la gestion de plusieurs versions d’un système, les diagrammes doivent être versionnés en parallèle du code. Cela permet aux équipes de comparer les évolutions architecturales au fil du temps. Cela aide à répondre à des questions telles que : « Comment ce module a-t-il évolué au cours des deux dernières versions ? »
Intégration avec les IDE : De nombreux environnements modernes proposent une génération de diagrammes en temps réel. Cela permet aux développeurs de voir immédiatement l’impact d’un changement. Cependant, ceux-ci sont souvent locaux. Pour une visibilité à l’échelle de l’équipe, un référentiel centralisé de diagrammes générés est nécessaire.
Tendances futures et intégration de l’IA 🤖
Le domaine évolue. La prochaine génération d’outils intègre l’intelligence artificielle pour combler le fossé sémantique.
- Traitement du langage naturel : Les outils futurs pourraient lire les commentaires de code et les messages de validation pour ajouter du contexte au diagramme. Cela pourrait étiqueter les relations en fonction de la logique décrite dans le code, et non seulement de la syntaxe.
- Reconnaissance de motifs : L’IA peut identifier automatiquement les motifs de conception. Au lieu de simplement dessiner une classe, l’outil pourrait l’étiqueter comme « Observateur » ou « Usine » en fonction de l’implémentation.
- Analyse prédictive : Certaines plateformes commencent à suggérer des changements structurels. Si un diagramme montre un fort couplage, l’outil pourrait suggérer de scinder un module.
Ces avancées promettent de dépasser le simple mappage structurel pour atteindre une intelligence architecturale. Toutefois, le principe fondamental reste inchangé : le code est la source de vérité.
Questions fréquemment posées ❓
Les outils automatisés peuvent-ils gérer les microservices ?
Oui, mais avec des précautions. L’architecture des microservices implique plusieurs dépôts. Un outil doit être configuré pour agréger les données entre les services. Il peut montrer les dépendances entre services, mais ne peut pas afficher la logique interne de chaque service dans une seule vue sans configuration importante.
Est-il préférable de documenter avant ou après le codage ?
Pour la génération automatisée, le code vient en premier. Vous ne pouvez pas générer un diagramme à partir de rien. Cependant, vous pouvez générer un diagramme à partir d’un squelette ou de code d’ébauche pour visualiser la structure prévue avant de remplir la logique.
Cela remplace-t-il le besoin d’un architecte logiciel ?
Non. Cela remplace le besoin d’un rédacteur de documentation. L’architecte reste nécessaire pour définir les modèles, les contraintes et la logique métier. L’outil ne fait que visualiser le résultat de ces décisions.
Comment gérer les bibliothèques propriétaires ?
Les outils automatisés ont souvent du mal avec les bibliothèques à code source fermé. Ils peuvent les traiter comme des boîtes noires. Vous pouvez souvent configurer l’outil pour traiter des noms de paquets spécifiques comme des dépendances externes, ce qui réduit le bruit dans le diagramme.
Et si le diagramme est trop grand ?
Utilisez la navigation et le filtrage. La plupart des outils vous permettent de cliquer sur une classe pour voir ses détails, en masquant le reste. N’essayez pas de faire tenir toute l’architecture d’entreprise sur un seul écran. Divisez-la par domaine.
Pensées finales 🏁
La génération automatisée des diagrammes de classes UML est une capacité puissante pour l’ingénierie logicielle moderne. Elle résout le problème persistant du décalage de la documentation et offre une visibilité immédiate sur la structure du système. Toutefois, elle ne remplace pas une conception réfléchie.
Le succès dépend du fait de considérer le diagramme comme un artefact dynamique dérivé du code, plutôt qu’un document statique à maintenir séparément. Lorsqu’elles sont correctement intégrées dans le cycle de développement, ces outils améliorent la collaboration et réduisent la charge cognitive. Ils permettent aux équipes de se concentrer sur la résolution de problèmes plutôt que sur le dessin de boîtes.
L’essentiel est l’équilibre. Utilisez l’automatisation pour la structure, et l’expertise humaine pour l’intention. Ensemble, ils créent une fondation architecturale solide qui soutient la croissance et les changements.

