











アジャイル開発の急速な変化する世界では、進捗はしばしば一貫した価値の提供能力によって測定される。しかし、最も規律正しいチームですら、動きを止めてしまう障害に直面することがある。このような障害は「障害(Impediment)」と呼ばれる。放置されると、速度の低下、士気の低下、リリースの遅延を引き起こす。迅速に障害を特定し、除去する方法を理解することは、あらゆるスクラムチームにとって重要な能力である。
このガイドは、ブロッカーの管理について包括的に解説する。定義、特定戦略、除去のワークフロー、予防策について検討する。目的は、流れを維持し、チームが不要な摩擦なく価値創造に集中できるようにすることである。
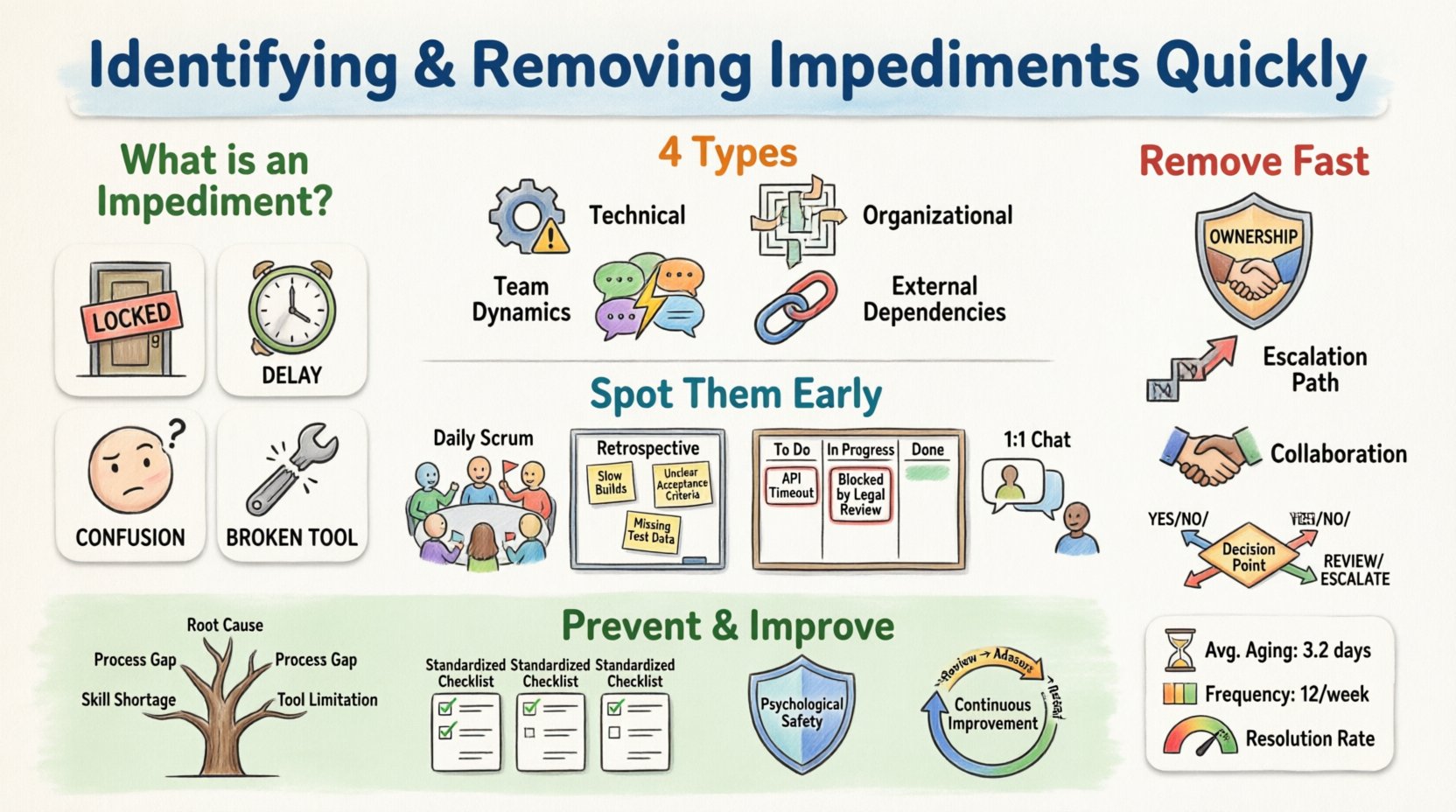
🔍 障害の定義
障害とは、スクラムチームのメンバーが作業を進められないようなあらゆる障害を指す。単なる「バグ」や「難しいタスク」とは異なる。進捗を妨げる外部的または内部的な要因である。通常の作業項目とは異なり、障害は製品に価値を加えるものではない。時間とエネルギーを消費するためだけに存在する。
- 外部的:他のチームへの依存、インフラ構成の問題、承認の遅延など。
- 内部的:知識不足、ツールの制限、要件の不明瞭さなど。
これらの問題を早期に特定することは非常に重要である。ブロッカーが早く認識されれば、スプリント目標に影響が及ぶ前に対処できる。
📋 障害の種類
すべてのブロッカーが同じというわけではない。一部は技術的なものであり、他のものは組織的なものである。分類することで、適切なリソースを割り当てて解決できる。以下の表は、一般的なカテゴリとその例を示している。
| カテゴリ | 説明 | 例 |
|---|---|---|
| 技術的 | コード、アーキテクチャ、ツールに関する問題。 | 環境のダウンタイム、レガシーコードの複雑さ、ビルド失敗。 |
| 組織的 | 官僚的またはプロセス関連の障壁。 | 承認プロセスの遅さ、ガバナンスの不明瞭さ、リソースの配分。 |
| チームのダイナミクス | 協働やコミュニケーションから生じる問題。 | 対立、共有理解の欠如、可用性のギャップ。 |
| 外部依存 | 直近のチーム外から来るブロッカー。 | 他のグループからのAPI、サードパーティベンダーの遅延。 |
👀 認識のための戦略
障害は、忙しいスケジュールの影に隠れがちである。チームは、それらを浮き彫りにするために積極的でなければならない。単一の情報源に頼るだけではほとんど十分ではない。代わりに、複数のチャネルを活用することで、見逃すことがないよう保証できる。
1. デイリースクラム
デイリースクラムは障害の特定の主な場です。各チームメンバーは標準的な質問に答えますが、特に自分を妨げていることを強調する必要があります。これは経営向けの進捗報告ではなく、チームの同期ポイントです。
- 具体的な表現を促す:「私は~によってブロッキングされています…」という表現を、「私は~に取り組みます…」という表現よりも推奨する。
- 焦点を保つこと。チームが10分以上問題解決に取り組み始めたら、それをオフラインに移す。
- 障害を目に見える形で記録する。物理ボードまたはデジタル追跡システムを使用する。
2. レトロスペクティブ分析
デイリースクラムは即時的な障害に対処する一方、レトロスペクティブは構造的な問題に取り組みます。特定の種類の障害が繰り返し現れる場合は、プロセス上の欠陥を示しています。
- パターンを探る。同じチームが常に遅延しているのか?
- 根本原因について議論する。なぜまた同じことが起きたのか?
- 再発防止のためのアクションアイテムにコミットする。
3. ビジュアルマネジメント
ワークボードは流れの即時可視化を提供する。カードが「進行中」に長期間留まっている場合は、潜在的な問題を示している。
- WIP(進行中作業)の上限を設定する。列が満杯なら、新たな作業は入らない。
- 色分けを使用する。赤いカードはブロッキングされた項目を示す。
- 計画会議やレビュー会議中にボードを確認し、止まっている項目を発見する。
4. 1on1の対話
時折、個人はグループの場でブロッカーを挙げることをためらう。プライベートな対話は、個人的またはセンシティブな障害を明らかにすることができる。
- 参加意欲が低いと感じられるチームメンバーに確認する。
- 彼らのワークフローについてオープンエンドの質問をする。
- ブロッカーを認めることを責任ある行動と見なす安全な環境を創出する。
⚙️ 障害除去プロセス
障害が特定されると、焦点は解決へと移る。スピードが重要だが、除去の方法も重要である。ブロッカーを素早く取り除くことは、品質チェックを無視することを意味しない。それは効率的な問題解決を意味する。
1. 所有権と責任
すべての障害には所有者がいる必要がある。所有権の曖昧さは行動の停止を招く。スクラムマスターはしばしばファシリテーターとして機能するが、チーム全体が責任を共有しなければならない。
- 障害を特定の人物に割り当てる。
- 予想される解決時間を定義する。
- ブロッカーが解消されるまで進捗を追跡する。
2. エスカレーション経路
チームメンバーが合理的な時間内に問題を解決できない場合は、エスカレーションしなければならない。誰に連絡すべきかを明確な階層で設定するべきである。
- チームレベル:同僚または社内の専門家(SME)。
- スクラムマスター層: プロセス上の障壁やリソースの衝突。
- マネジメント層: 戦略的決定や外部ベンダーの問題。
エスカレーションを失敗と見なしてはならない。それは作業が継続されるようにするための仕組みである。リーダーシップに「迷惑をかける」ことを避けるためにエスカレーションを遅らせるのは、問題自体よりも多くの損害をもたらすことが多い。
3. 壁を作らずに協働する
障害はしばしば複数の機能領域からの意見が必要となる。チームは孤立して作業してはならない。
- 関係するステークホルダーを招集して、素早いミーティングを開催する。
- 問題を小さな、管理しやすい部分に分解する。
- 将来の発生を防ぐために知識を共有する。
4. 決定の仕方
時折、障害に対処するには技術的でない決定が必要となる。スピードと品質の間のトレードオフ、あるいは範囲とスケジュールの間のトレードオフである可能性がある。
- プロダクトオーナーが範囲に関する決定を下せるように権限を与える。
- チームが解決策を選択するための技術的自律性を持っていることを確認する。
- 決定内容とその根拠を文書化する。
🛡️ 予防とカルチャー
反応的な除去は良いが、予防的な対策の方がさらに良い。障害を抑制する文化を構築することで、システム内の摩擦を減らすことができる。
1. 根本原因分析
ブロッカーが取り除かれた後は、「なぜ?」と5回尋ねる。この手法は症状の対処ではなく、根本原因を突き止めるのに役立つ。
- 問題: ビルドサーバーがクラッシュした。
- なぜ? ディスク容量が満杯だった。
- なぜ? ログのローテーションが行われていなかった。
- なぜ? 自動化スクリプトがなかった。
- なぜ? インfraチームがその対応を優先しなかった。
- 修正: ログのローテーションを自動化し、アラートを設定する。
2. 標準化
一貫性があることで混乱が減る。全員が同じセットアップおよびデプロイプロセスに従えば、エラーの発生が少なくなる。
- 環境を管理するために、インフラストラクチャをコードとして利用する。
- コーディング規約とレビューのプロセスを標準化する。
- オンボーディングやデプロイなど、一般的なタスク用のチェックリストを作成する。
3. 心理的安全性
チームメンバーは、意見を述べることに安全を感じる必要がある。責められることを恐れれば、障害を隠し続け、対処が遅れてしまう。
- 人ではなくプロセスに注目する。
- 問題の発見を成功として祝う。
- 失敗についての透明性を促進する。
4. 持続的改善
システムは進化しなければならない。昨年は機能したことが、今日では機能しない可能性がある。定期的にワークフローをレビューする。
- サイクルタイムとリードタイムを測定する。
- バリューストリームにおけるボトルネックを特定する。
- 低リスクの領域で、新しいツールやプロセスの試行を行う。
📊 メトリクスと追跡
障害を効果的に管理するためには、それらを測定しなければならない。データによって、摩擦が生じる場所が明らかになる。
1. 障害の経過時間
障害が開かれたままになっている期間を追跡する。平均的な経過時間が長いほど、システム的な問題を示している。
- ブロッカーの最大年齢に目標を設定する。
- すべてのリトロスペクティブで、経過時間が長い項目を確認する。
- しきい値を超えた項目を強調する。
2. 発生頻度
特定の種類の障害がどれだけ頻繁に発生するかをカウントする。これにより、繰り返し現れるテーマが明らかになる。
- 障害をカテゴリ(例:インフラストラクチャ、承認)ごとに分類する。
- 頻度を時間軸でプロットして、トレンドを確認する。
- 最も頻繁に発生するカテゴリから順に対処する。
3. 解決率
スプリント内に解決された障害の割合を測定する。低い解決率は、より良いリソースや迅速なエスカレーションの必要性を示唆する。
- 計算式: (解決済みの障害数 / 合計障害数) × 100。
- 異なるスプリント間で比較する。
- この指標を活用して、チームの能力計画を調整する。
🚦 避けたい一般的な落とし穴
最高の意図を持っていても、チームはしばしば進捗を妨げる罠に陥ることがある。これらの落とし穴に気づくことが、それらを避ける第一歩である。
- 小さなブロッカーを無視する:小さな問題はしばしば大きな危機に発展する。すぐに対処する。
- 個人を責める:責めることは恐怖の文化を生む。システムに注目する。
- スクラムマスターへの過度な依存:スクラムマスターはファシリテートするが、作業の責任はチームにあり、障害の除去はチーム全体の努力であるべきだ。
- 可視性の欠如:ブロッカーが可視化されていなければ、追跡できない。視覚的なボードを使用する。
- 誤った解決策:根本原因を理解せずに即効的な対処を施すと、再発の可能性が高くなる。
🤝 ステークホルダーとの連携
障害はしばしば開発チーム外の人々に関わる。これらの関係を管理することは重要である。
- 透明性:ブロッカーによる遅延について、ステークホルダーに常に情報を共有する。
- 期待値の管理:外部の依存関係が及ぼす影響を理解していることを確認する。
- フィードバックループ:定期的にステークホルダーに、そのニーズが満たされているか確認する。
- 共同での問題解決:複雑なブロッカーの解決に、ステークホルダーを参加させる。
💡 最後の考え
障害の管理は一度きりの作業ではない。注意深さとコミットメントが求められる継続的なプロセスである。ブロッカーの定義を明確にし、識別方法を明確にし、構造化された除去プロセスを順守することで、チームは高い速度を維持できる。予防が最終的な目標だが、迅速な対応が可能であることは、プロジェクトを軌道に乗せ続けるための安全網となる。
思い出そう。スクラムガイドでは、スクラムマスターは障害を排除するサーヴァントリーダーとして定義されている。しかし実際には、チーム全体がこの責任を共有している。すべての人が声を上げたり行動したりできるようになると、作業の流れがスムーズになり、価値の提供もより予測可能になる。
今日から、現在のバックログを見直すことを始める。リスクがある項目を特定し、責任者を割り当て、進捗を確認する時間を設定する。小さな行動が、時間の経過とともに大きな改善をもたらす。

