



ソフトウェアアーキテクチャは、1行のコードを書く前に問題領域をどれだけ正確に理解できるかに大きく依存する。この理解の中心にはドメインモデルがある。ドメインモデルは、特定のビジネス領域の核心的な概念、振る舞い、ルールを表す。それはシステムの論理の設計図として機能する。しかし、抽象的な概念はステークホルダー、開発者、アナリストの間で伝えるのが難しい。これが、統合モデル言語(UML)クラス図が不可欠なツールとなる理由である。
クラス図は、システムの静的ビューを提供し、振る舞いではなく構造を捉える。チームがエンティティ、属性、関係を標準化された形式で可視化できる。適切に使用すれば、これらの図は曖昧さを減らし、技術的実装をビジネス要件と一致させる。可視化の正確さが、結果として得られるコードが時間の経過とともに保守可能で堅牢なままであることを保証する。
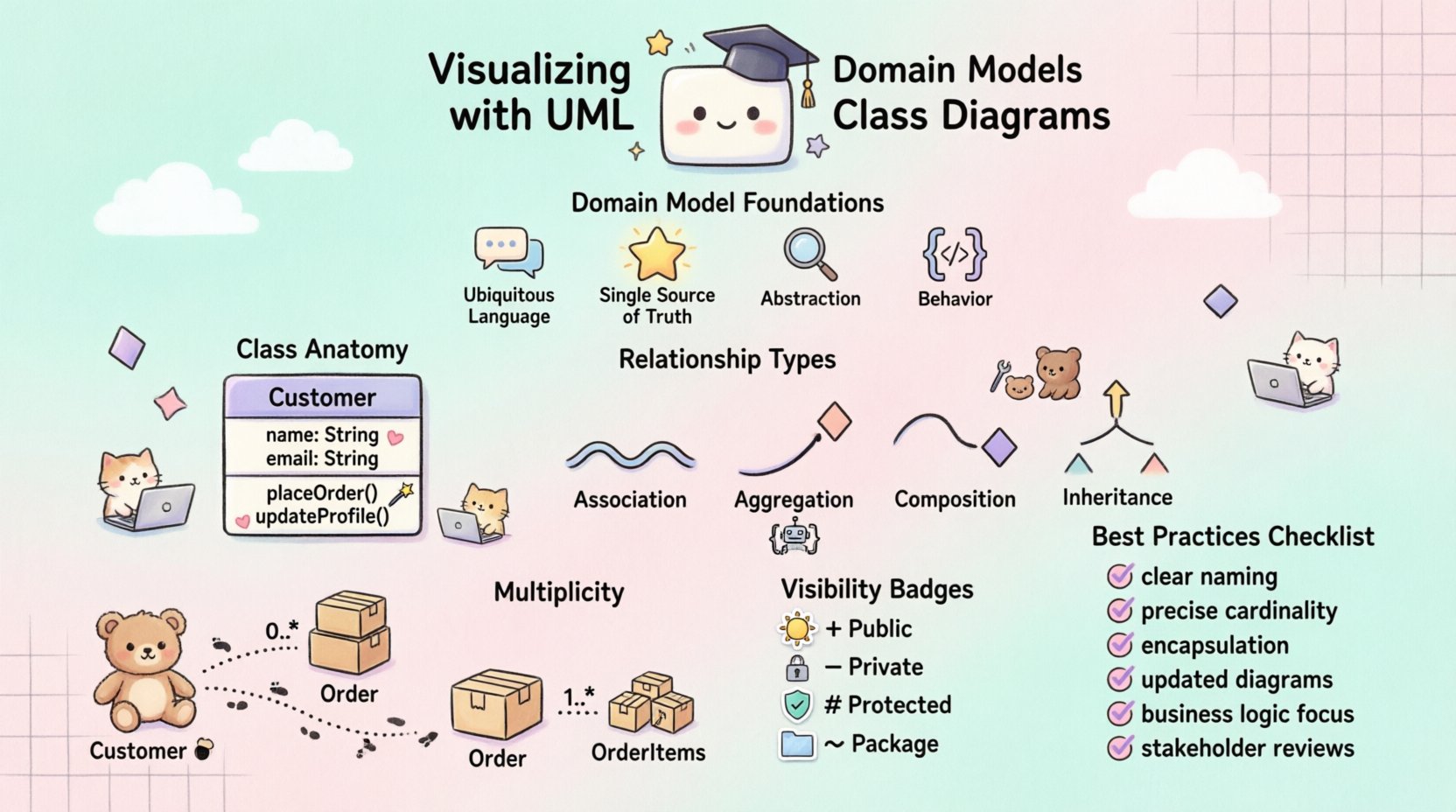
ドメインモデリングの基盤 🧠
線やボックスを描く前に、モデルの目的を理解する必要がある。ドメインモデルはデータベーススキーマではない。それはビジネスロジックの表現である。両者を混同すると、硬直的で適応が難しいシステムになってしまう。主な目的は、ビジネスルールの本質を捉えることである。
重要な原則には以下が含まれる:
- 普遍的言語:ステークホルダーが自然に理解できる用語を使用する。
- 唯一の真実の源:モデルは合意された論理を反映すべきである。
- 抽象化:関係のない詳細を無視し、本質的な概念に焦点を当てる。
- 振る舞い:エンティティがどのように振る舞うかを定義する操作を含める。
これらの原則に従うことで、図は単なる技術的成果物ではなく、コミュニケーションのツールとなる。非技術的なビジネスオーナーと技術的なエンジニアの間の溝を埋める。
クラス図の構造 🏗️
クラスの構成要素を理解することは、正確な図を描くための基盤である。各クラスは通常、3つのセクションで構成される。上部のセクションには名前が入る。中央には属性が入る。下部にはメソッドまたは操作が入る。適切な分離により、明確さが保たれる。
クラス名
クラス名は、ドメイン内のエンティティを表す名詞でなければならない。PascalCaseで大文字で始める必要がある。例えば、Customer または Order は標準的な表記である。文脈が厳密に定義されていない限り、Item などの汎用的な名前は避けるべきである。名前の明確さは、実装時に混乱を防ぐ。
属性
属性はオブジェクトの状態を定義する。型を持ち、明確なスコープを持つべきである。例えば、Customer には name(文字列) と an 年齢(整数)。可視性修飾子はここでは重要です。プライベートな属性は内部用であり、パブリックな属性は外部からアクセス可能です。この違いがデータの整合性を保護します。
操作
操作は振る舞いを定義します。これらはクラスの状態を操作するメソッドです。An 注文 クラスには an calculateTotal() 操作があります。操作にも可視性修飾子を設定する必要があります。プライベートな操作はヘルパー関数であり、パブリックな操作は他のクラスとのインターフェースを構成します。
関係の管理 🔗
クラスは孤立して存在することはめったにありません。関係を通じて他のクラスと相互作用します。これらの関係は、オブジェクトがどのように接続されているか、そして互いにどのように影響し合うかを定義します。関係にはいくつかの種類があり、それぞれが特定の意味と表記を持っています。
| 関係の種類 | 表記 | 意味 |
|---|---|---|
| 関連 | 実線 | クラス間の一般的な接続。 |
| 集約 | 空のダイヤモンド | 部分が独立して存在できる全体-部分関係。 |
| 合成 | 塗りつぶされたダイヤモンド | 部分が独立して存在できない強い全体-部分関係。 |
| 継承 | 空の三角形を備えた矢印 | 子クラスが親クラスから継承する一般化。 |
集約と合成の違いを理解することは重要です。集約では、a 部門 には 従業員しかし、部署が閉鎖されても、従業員は依然として存在する。コンポジションにおいては、家には部屋がある。家が取り壊されれば、部屋は存在しなくなる。この違いは、データの管理と永続化の仕方にとって影響を与える。
基数と多重度
関係は単に二項的ではない。多くの場合、数量を伴う。多重度は、あるクラスのインスタンスが、別のクラスのインスタンスと何個関係を持つかを定義する。一般的な表記法には以下がある:
- 1:正確に1つのインスタンス。
- 0..1:0個または1個のインスタンス。
- 1..*:1個以上(1つまたはそれ以上)のインスタンス。
- *:多数のインスタンス(0..*と同じ)。
たとえば、顧客が0..* 注文を出す。1つの注文には1..* 注文項目が含まれる。この正確さにより、データベース設計やコーディング中に論理的な誤りを防ぐことができる。
継承戦略 🔄
継承により、クラスは共通の属性や振る舞いを共有できる。これによりコードの再利用が促進され、階層構造が確立される。しかし、慎重に使用する必要がある。過剰な使用は、維持が難しい深い階層構造を生じる原因となる。
継承を設計する際には:
- IS-A関係: 子クラスが親クラスの種類であることを確実にします。A
車は車両。A車は車輪. - 抽象化:インスタンス化できない概念(例:)には抽象クラスを使用します。
支払い方法. - ポリモーフィズム: 異なるクラスが同じメソッド呼び出しに異なる反応を許可する。
デメリットを検討する。継承は強い結合を生む。親クラスが変更されると、子クラスが壊れる可能性がある。コンポジションのような代替手段は、場合によってより柔軟になることがある。決定はドメインモデルの安定性に依存する。
可視性とスコープ 👁️
可視性はクラスメンバーへのアクセスを制御する。これはカプセル化の基本的な側面である。標準的な可視性レベルは4つある。
- パブリック (+): どこからでもアクセス可能。インターフェースには控えめに使用する。
- プライベート (-): クラス内でのみアクセス可能。内部状態を保護する。
- プロテクト (#): クラスおよびサブクラス内でアクセス可能。
- パッケージ (~): 同じパッケージまたは名前空間内でアクセス可能。
デフォルトでプライベートな可視性を採用することは安全な実践である。パブリック操作を通じて必要なものだけを公開する。これにより、予期しない副作用のリスクを最小限に抑えることができる。また、後でクラスをリファクタリングしやすくなる。
一般的なモデル化の誤り ⚠️
経験豊富な実務家ですら誤りを犯す。これらの落とし穴を早期に特定することで、開発中に大幅な時間を節約できる。
- データベース中心の設計: オブジェクトではなくテーブルをモデル化する。これによりビジネスロジックや振る舞いが無視される。
- 過剰設計: あまりにも多くの関係性や抽象クラスを作成する。シンプルさを保つこと。
- Multiplicityを無視する: 関連するオブジェクトの数を定義することを忘れてしまう。これによりヌルポインタ例外が発生する。
- 命名の不整合: 単数と複数の名詞を混在させたり、camelCaseとPascalCaseを混在させたりする。
- 文書化の欠如: コンテキストやメモのない図は、将来の保守担当者にとって無意味である。
新たな視点でモデルをレビューすることで、これらの問題を発見できる。同僚によるレビューは品質維持に不可欠である。
反復的精練プロセス 🔄
ドメインモデルは進化する。要件は変化し、新しい機能が追加される。図はこの進化を反映すべきである。静的なモデルは死んだモデルである。
精練プロセスには以下の内容が含まれる:
- 検証: モデルがビジネスルールと一致しているか確認する。
- 最適化: 冗長なクラスや関係性を削除する。
- 標準化: すべての図が同じ表記規則に従っていることを確認する。
- バージョン管理: 時間の経過に伴うモデルの変更を追跡する。
定期的な更新により、ドキュメントの正確性が保たれる。この整合性は設計と実装のズレを防ぐ。
協働と文書化 🤝
図の質は、その図が促進する理解の質に依存する。すべてのチームメンバーがアクセスできるようにしなければならない。明確な表記と一貫したスタイルは不可欠である。
- 文脈的なメモ: 複雑な論理を説明するためにコメントを追加する。
- 可読性: ラインの交差を最小限に抑えるようにクラスを配置する。
- ツールの利用: エクスポートやバージョン管理をサポートする標準的なツールを使用する。
- 統合:トレーサビリティのために図をコードリポジトリにリンクする。
すべての人がモデルを理解すれば、コラボレーションがスムーズになる。誤解が減り、開発スピードが向上する。
モデルとコードの橋渡し 🧩
最終的な目標は、視覚的なモデルを動作するソフトウェアに変換することである。この変換はできるだけ直接的であるべきだ。コードジェネレーターは役立つが、複雑な論理については手動での実装が必要な場合が多い。
この移行におけるベストプラクティスには以下が含まれる:
- 一貫性:コードの構造が図の構造と一致するようにする。
- コメント:コードのコメントを使って、特定のモデル要素を参照する。
- テスト:操作で定義された振る舞いに基づいてテストを書く。
- リファクタリング:コードに大幅な変更がある場合は、図を更新する。
このフィードバックループにより、ドキュメントがシステムの真の反映のまま保たれる。
時間の経過に伴う明確さの維持 🌱
システムが拡大するにつれて、図はごちゃごちゃになりがちである。複雑さの管理は継続的な作業である。戦略には以下が含まれる:
- サブシステム:関連するクラスをパッケージにまとめる。
- プロファイル:スタereotypeを用いて、特定のクラスの種類を示す。
- レイヤー:プレゼンテーション層、ビジネス層、データ層を分離する。
モデルを論理的に整理することで、可読性を保つことができる。これにより、図がプロジェクトのライフサイクル全体を通じて有用なツールのままになることが保証される。
ベストプラクティスの要約 ✅
- 明確でドメイン固有の命名規則を使用する。
- 関係性を正確な基数で定義する。
- 可視性修飾子を通じてカプセル化を尊重する。
- コードの変更に合わせて図を更新する。
- データベーステーブルだけでなく、ビジネスロジックに注目する。
- 関係者と定期的にモデルをレビューする。
これらのガイドラインに従うことで、構築しやすく、変更しやすいシステムが得られる。可視化における正確さとは、線を描くことだけではなく、問題について明確に考えることにある。

