











Les écosystèmes logiciels modernes accumulent souvent des décennies d’histoire de développement. Lorsque de nouvelles équipes héritent de ces systèmes, elles doivent faire face à un réseau complexe de logique interconnectée, de comportements non documentés et d’une architecture en évolution. Tel est le réel visage du code hérité. Le comprendre n’est pas une option ; c’est une condition préalable à toute modification sûre et à une croissance durable. L’ingénierie inverse du code hérité à l’aide de diagrammes de classes UML offre une voie structurée vers la clarté. Elle transforme des fichiers sources opaques en modèles visuels compréhensibles qui révèlent comment le système fonctionne réellement.
Ce guide détaille la méthodologie pour analyser des bases de code existantes et construire des diagrammes de classes UML précis. Nous explorons les étapes techniques, les fondements théoriques et les bénéfices pratiques de la visualisation des structures orientées objet. À la fin, vous disposerez d’un cadre clair pour aborder même les environnements hérités les plus complexes.
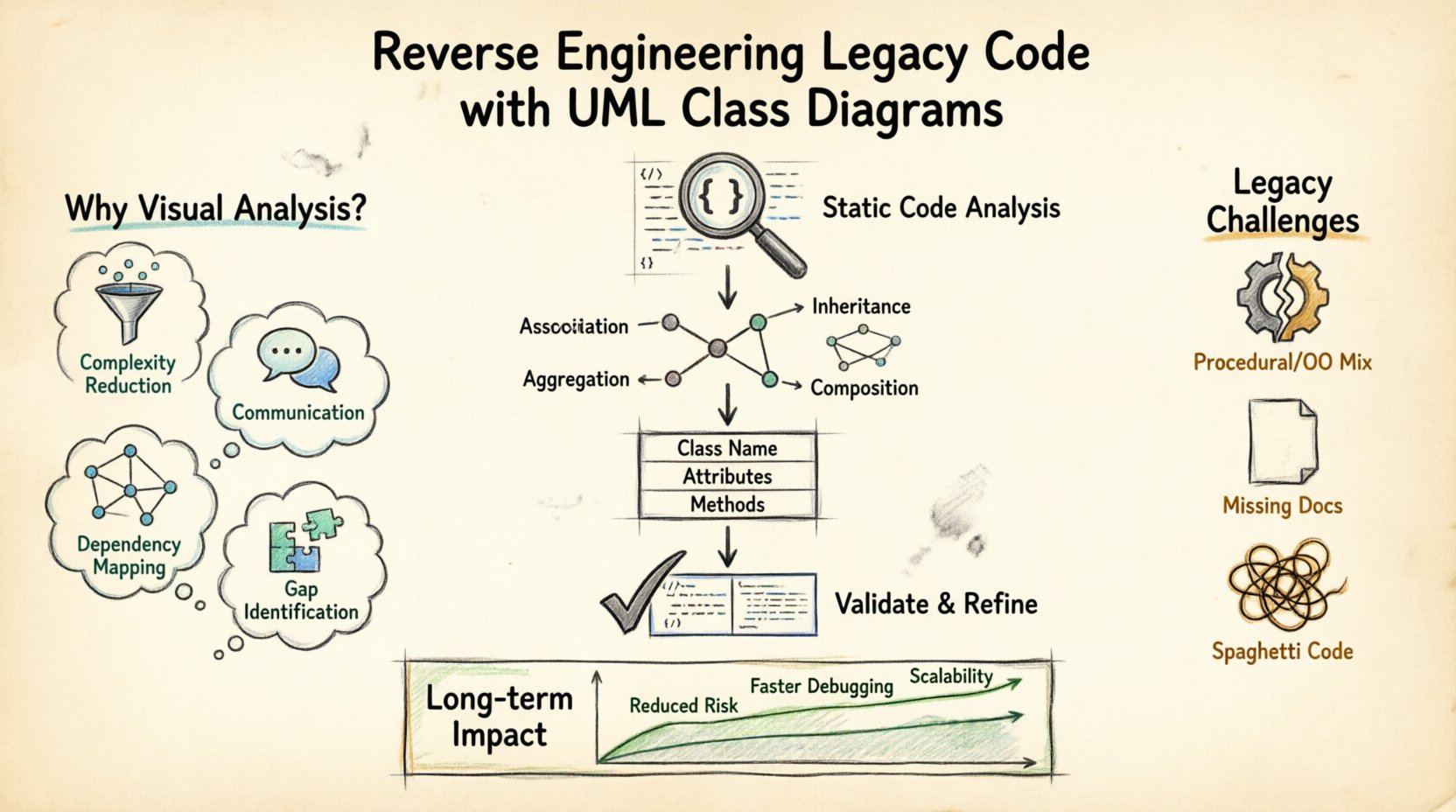
Pourquoi les systèmes hérités nécessitent une analyse visuelle 🕰️
Le code hérité souffre souvent d’un manque de documentation. Au fil du temps, les développeurs originaux partent, et le contexte derrière des décisions de conception spécifique s’estompe. Le code reste, mais le raisonnement devient flou. Se fier uniquement à la lecture du code source peut être inefficace et sujet à des malentendus. Les modèles visuels offrent une abstraction de niveau supérieur.
Pensez aux raisons suivantes qui rendent l’analyse visuelle essentielle :
- Réduction de la complexité :Les grandes bases de code contiennent des milliers de lignes de logique. Un diagramme condense cela en relations et entités gérables.
- Communication :Les parties prenantes et les nouveaux membres d’équipe comprennent plus rapidement les diagrammes que la syntaxe brute. Ils fournissent un langage commun pour discuter de l’architecture.
- Cartographie des dépendances :Les systèmes hérités ont souvent des dépendances cachées. Les visualiser aide à éviter les erreurs de régression lors de la refonte.
- Identification des écarts :Comparer le code existant à la conception initiale met en évidence les écarts et la dette technique.
Sans représentation visuelle, les modifications sont risquées. Vous pourriez modifier une classe sans vous rendre compte qu’elle rompt un lien critique dans un autre module. Les diagrammes agissent comme une sécurité, montrant l’ensemble de l’impact avant qu’une seule ligne de code ne soit modifiée.
Comprendre les fondamentaux des diagrammes de classes UML 📐
Le langage de modélisation unifié (UML) est une notation standard pour visualiser la conception du système. Le diagramme de classes est le type le plus courant utilisé pour l’ingénierie inverse. Il décrit la structure statique du système en affichant les classes, leurs attributs, leurs opérations et les relations entre les objets.
Lors de l’extraction de ces informations à partir du code, vous vous concentrez sur des éléments spécifiques :
- Nom de classe :Représente une entité ou un concept spécifique au domaine. Dans le code, cela correspond directement à une définition de classe.
- Attributs :Données stockées dans la classe. Elles correspondent aux variables membres ou propriétés.
- Méthodes :Comportements ou fonctions que la classe peut effectuer. Elles correspondent aux fonctions ou méthodes définies dans le code source.
- Relations :Connexions entre les classes qui définissent leur interaction.
L’objectif n’est pas de recréer le code ligne par ligne, mais de capturer l’intention architecturale. Cette abstraction vous permet de voir les motifs plutôt que les détails syntaxiques individuels.
Le flux de travail de l’ingénierie inverse 🔁
La construction d’un diagramme à partir de code brut est un processus systématique. Elle nécessite une analyse, une extraction et une validation. Aucun outil unique ne peut automatiser parfaitement ce processus dans toutes les situations, donc une surveillance humaine est essentielle. Le flux de travail suivant garantit précision et exhaustivité.
Étape 1 : Analyse statique du code
Commencez par analyser la base de code sans l’exécuter. Les outils d’analyse statique peuvent parser la structure pour identifier les classes, les méthodes et les types de variables. Cette étape fournit les données brutes nécessaires au diagramme.
- Identifiez toutes les définitions de classes.
- Listez les membres publics, privés et protégés.
- Cartographiez les imports et les dépendances externes.
Cette phase crée une liste d’entités. Vous n’avez pas besoin de comprendre la logique pour l’instant, seulement l’existence et la signature des composants.
Étape 2 : Identifier les relations
Une fois les classes listées, déterminez comment elles sont connectées. Recherchez les instanciations, l’héritage et les modèles d’utilisation. C’est le cœur du diagramme. Les relations définissent le flux de contrôle et de données.
Les types de relations courants incluent :
- Association : Un lien général entre des objets. Un objet utilise un autre.
- Héritage : Une relation spécialisée « est-un » où une classe étend une autre.
- Agrégation : Une relation « possède-un » où la partie peut exister indépendamment du tout.
- Composition : Une relation « possède-un » plus forte où la partie ne peut pas exister sans le tout.
Étape 3 : Cartographier vers un modèle visuel
Transférez les éléments identifiés vers un environnement de dessin. Placez les classes sous forme de boîtes et les relations sous forme de lignes. Assurez-vous de noter la cardinalité là où cela est pertinent (par exemple, un-à-plusieurs). Cette représentation visuelle est votre hypothèse de travail sur le système.
Étape 4 : Valider et affiner
Revoyez le diagramme par rapport au code. Toutes les méthodes du code apparaissent-elles dans le diagramme ? Toutes les relations sont-elles exactes ? Si le code a été fréquemment modifié, le diagramme pourrait être obsolète. Validez en suivant quelques chemins d’exécution à travers le code et le diagramme pour vous assurer qu’ils correspondent.
| Phase du flux de travail | Action clé | Sortie |
|---|---|---|
| Analyse statique | Analyser les fichiers sources | Liste des classes et des membres |
| Cartographie des relations | Suivre les dépendances | Connexions définies entre les classes |
| Construction visuelle | Dessiner un diagramme | Modèle UML initial |
| Validation | Vérification du code vers le diagramme | Modèle d’architecture vérifié |
Relations clés à identifier 🕸️
Comprendre la nature des connexions est essentiel pour une ingénierie inverse précise. Une mauvaise interprétation d’une relation peut conduire à des hypothèses erronées sur le comportement du système. Voici une analyse plus approfondie de la manière d’identifier celles-ci dans le code.
Héritage (généralisation)
Recherchez les mots-clés indiquant une extension ou une implémentation. Dans de nombreux langages orientés objet, cela est explicite. Une classe parente définit un comportement commun, tandis que les classes filles le spécialisent.
- Vérifiez les références à la classe de base dans les définitions de classe.
- Identifiez les méthodes redéfinies dans les sous-classes.
- Suivez la hiérarchie du plus générique au plus spécifique.
Cette structure est souvent un signe d’un bon design, mais dans le code ancien, elle peut devenir profonde et compliquée. Assurez-vous que la chaîne d’héritage a un sens logique.
Association et dépendance
Ce sont souvent les liens les plus courants. Une association existe lorsque une classe détient une référence à une autre. Une dépendance est une relation temporaire, comme un paramètre de méthode.
- Vérifiez les arguments du constructeur pour voir quelles classes sont nécessaires.
- Recherchez les paramètres de méthode qui indiquent une utilisation.
- Identifiez les variables membres qui détiennent des références à d’autres classes.
Différencier une association forte d’une dépendance temporaire est important. Les associations fortes impliquent que les classes sont étroitement couplées, tandis que les dépendances suggèrent une interaction plus lâche.
Défis courants dans les environnements de code ancien ⚠️
Le code ancien ne suit pas toujours les modèles de conception modernes. Vous pouvez rencontrer des irrégularités structurelles qui rendent le dessin de diagrammes difficile. Reconnaître ces défis vous aide à adapter votre approche.
Code procédural dans des systèmes orientés objet
Beaucoup de systèmes évoluent au fil du temps. Un projet peut commencer de manière procédurale puis passer à une approche orientée objet. Cela donne lieu à un code qui mélange des styles. Vous pouvez trouver des fonctions globales agissant comme des classes, ou des classes sans comportement significatif.
- Traitez les modules procéduraux comme des composants indépendants.
- N’essayez pas de les forcer dans des structures de classe s’ils ne s’y adaptent pas.
- Documentez-les comme des blocs fonctionnels plutôt que comme des objets.
Manque de commentaires et de conventions de nommage
Les anciens bases de code manquent souvent de documentation. Les noms de variables peuvent être abrégés ou incohérents. Cela rend difficile l’inférence de la finalité d’une classe.
- Regardez les noms de méthode pour trouver des indices sur la fonctionnalité.
- Suivez le flux de données pour comprendre ce qu’une variable contient.
- Utilisez le contexte du code environnant pour inférer le sens.
Code spaghetti et couplage étroit
Au fil du temps, les classes peuvent devenir entremêlées. Modifier l’une pourrait briser l’autre de manière inattendue. Cela rend le graphe de dépendances dense et difficile à lire.
- Concentrez-vous d’abord sur les modules de haut niveau pour simplifier la vue.
- Utilisez le codage par couleur pour mettre en évidence les groupes fortement couplés.
- Identifiez les interfaces ou les couches d’abstraction qui séparent les préoccupations.
Du schéma à la documentation 📝
Le résultat final de ce processus est une documentation qui facilite le développement futur. Un diagramme de classes UML n’est pas seulement une image ; c’est une spécification de la structure du système. Cette documentation remplit plusieurs fonctions.
Intégration :Les nouveaux développeurs peuvent étudier le schéma pour comprendre l’architecture avant de lire des fichiers spécifiques. Cela réduit le temps nécessaire pour devenir productif.
Planification du restructurage : Avant de faire des modifications, le schéma aide à identifier les classes concernées. Il agit comme une carte routière pour des modifications sûres.
Communication : Lorsqu’on discute de modifications du système avec la direction ou les clients, le schéma fournit un support visuel clair que le jargon technique ne peut pas transmettre.
Assurez-vous que la documentation est tenue à jour. Si le code change, le schéma doit être mis à jour. Un schéma obsolète est pire qu’aucun schéma, car il crée une fausse confiance.
Meilleures pratiques pour l’exactitude ✅
Pour maintenir l’intégrité de l’effort de reverse ingénierie, suivez ces directives. La cohérence et la rigueur sont essentielles.
- Commencez au niveau élevé :Commencez par les principaux sous-systèmes. Ne vous perdez pas immédiatement dans les détails. Définissez d’abord les composants majeurs.
- Utilisez une notation standard :Restez fidèle aux symboles standards UML. Cela garantit que quiconque familier avec la norme peut lire le schéma sans confusion.
- Validez avec des parcours de code :Parcourez régulièrement l’exécution du code pour vérifier que le schéma correspond à la réalité.
- Documentez les hypothèses : Si vous êtes incertain sur une relation, notez-le. Ne devinez pas. Marquez les zones incertaines pour un examen ultérieur.
- Itérez : L’ingénierie inverse est rarement une tâche ponctuelle. À mesure que vous comprenez mieux le système, affinez le schéma.
Impact à long terme sur la maintenance 📈
Investir du temps dans l’ingénierie inverse rapporte à long terme. Elle réduit la dette technique en rendant le système transparent. Lorsque l’architecture est claire, il est plus facile d’identifier les zones nécessitant des améliorations.
Réduction des risques :Avec une carte claire des dépendances, le risque de casser le système lors des mises à jour diminue considérablement. Vous savez exactement ce qui sera affecté.
Débogage plus rapide :Lorsqu’une erreur survient, le diagramme aide à suivre le flux des données. Vous pouvez voir quelle classe est responsable d’une action spécifique.
Évolutivité :Comprendre la structure actuelle vous permet de prévoir la croissance. Vous pouvez identifier les goulets d’étranglement et concevoir de nouveaux composants qui s’intègrent à l’architecture existante.
Le code hérité est souvent perçu comme une charge. Cependant, avec les bons outils et une méthodologie appropriée, il devient un atout. Les diagrammes de classes UML comblent le fossé entre le vieux code et la nouvelle compréhension. Ils transforment l’incertitude en connaissance.
Conclusion du processus 🎯
L’ingénierie inverse du code hérité est une tâche rigoureuse. Elle exige de la patience, une attention aux détails et une bonne compréhension de l’architecture logicielle. En utilisant des diagrammes de classes UML, vous créez un document vivant qui évolue avec le système. Cette approche garantit que les connaissances intégrées dans le code sont préservées et accessibles.
Commencez par les bases. Identifiez les classes. Cartographiez les relations. Validez le modèle. Cette approche systématique conduit à une compréhension plus claire du système. Elle permet aux équipes de maintenir, mettre à jour et étendre le logiciel avec confiance. L’effort investi dans la visualisation se traduit par une stabilité et une maintenabilité accrues.
Souvenez-vous que l’objectif est la clarté, pas la perfection. Un diagramme à 90 % exact est souvent plus utile qu’un diagramme incomplet. Concentrez-vous sur les chemins critiques et les composants majeurs. Utilisez le diagramme comme un outil de réflexion, et non seulement comme un artefact statique. À mesure que le système évolue, votre compréhension doit évoluer aussi. Gardez la documentation en phase avec le code.
En suivant ces étapes, vous transformez un défi lié au code ancien en une tâche d’ingénierie gérable. Le code devient lisible. L’architecture devient transparente. L’avenir du système devient sécurisé.

